

OpenAI 공동 창업자이자 Tesla AI 디렉터를 역임한 Andrej Karpathy는 2025년 12월을 기점으로 직접 코드를 작성하는 비중이 80%에서 거의 0%로 급감했다고 밝혔습니다. 에이전트가 코딩을 대신하게 되면서, 연구자의 시간이 코드 작성이 아닌 다른 곳으로 이동했습니다.
그렇다면 실패를 분석하고, 논문을 읽고, 개선 방향을 찾는 과정도 에이전트가 대신할 수 있을까. Auto Research는 그 질문에서 출발했습니다. 실험을 설계하고, 실패를 분석하고, 논문을 검색하고, 코드를 수정하는 과정 전체를 에이전트가 자율적으로 반복할 수 있다면, 연구자도 병목에서 빠질 수 있습니다.
Enhans는 이 방식을 독자적인 설계로 구현했습니다. 실패 분석과 학술 문헌 검색을 하나의 루프로 연결한 Auto Research AI 시스템입니다.
기존 AutoML이 해결하지 못한 문제
Neural Architecture Search, Hyperparameter Optimization 같은 기존 AutoML 접근법은 미리 정의된 파라미터 범위 안에서만 탐색합니다. 탐색 공간을 사람이 먼저 설계해야 하고, 그 범위 밖은 탐색하지 못합니다.
에이전트의 행동 전략, 환경 상호작용 로직, 에러 복구 메커니즘처럼 코드의 구조적 로직을 바꾸는 것은 파라미터 탐색의 영역이 아닙니다. 기존 AutoML은 파라미터 숫자를 조정하는 것에 그칩니다. 에이전트가 실패했을 때 왜 실패했는지를 분석하고, 전략 자체를 바꾸는 것은 할 수 없습니다.
학술 문헌 활용도 마찬가지입니다. 기존 AutoML 시스템에는 최신 연구 성과를 자동으로 수집하고 개선 전략에 반영하는 메커니즘이 없습니다. 연구자가 논문을 읽고 아이디어를 추출하는 과정은 여전히 완전한 수동 작업입니다.
이 두 가지 문제를 Enhans는 Auto Research로 풀고자 했습니다.
Auto Research AI 시스템 아키텍처
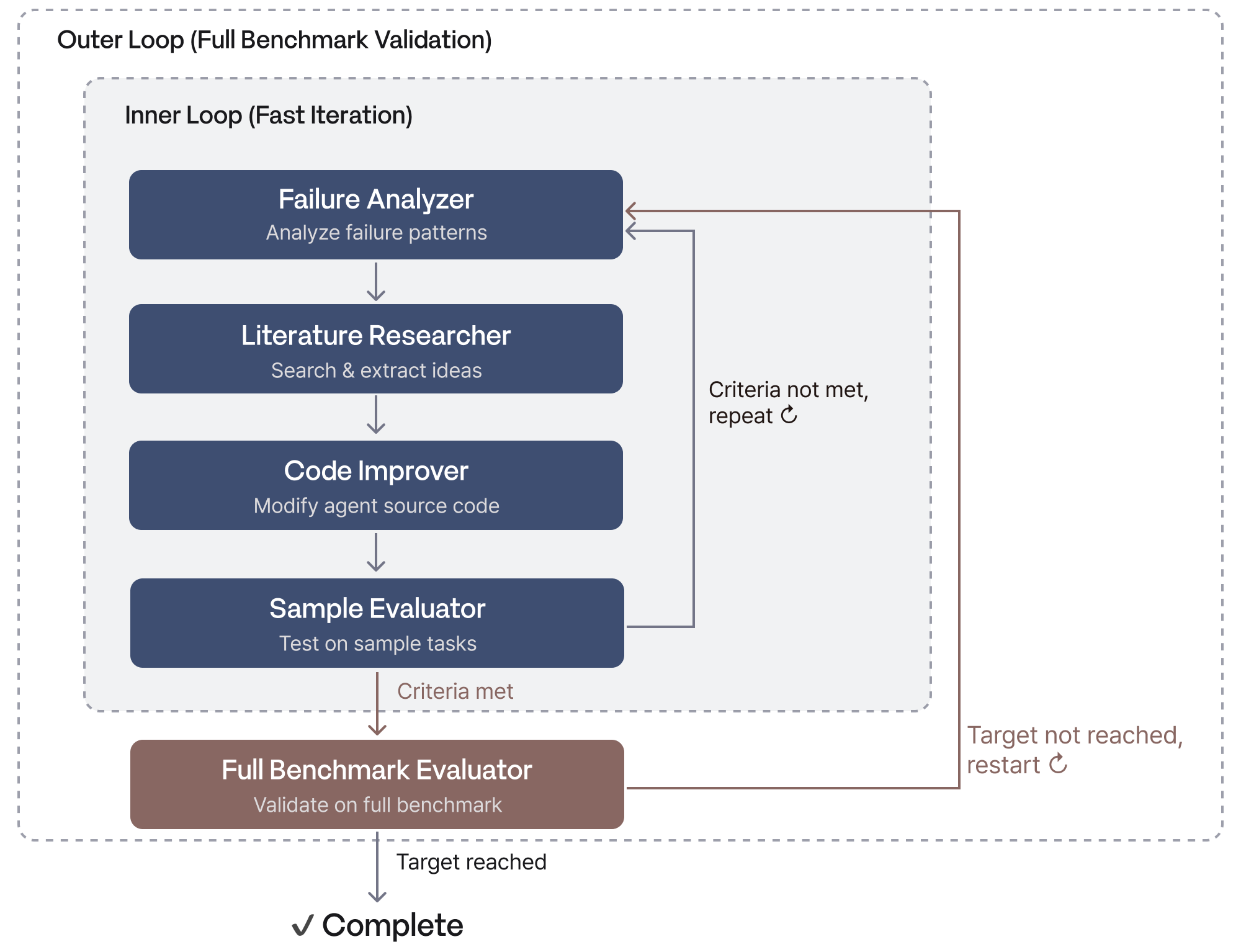
시스템은 크게 세 계층으로 구성됩니다. 오케스트레이터가 전체 실행 흐름을 제어하고, 이중 루프 엔진이 연구 사이클을 반복하며, 각 단계의 에이전트가 전문 역할을 수행합니다.
- 오케스트레이터: 실패 분석, 논문 조사, 코드 개선 등 각 연구 단계를 독립적인 LLM 세션으로 실행합니다. 초기 실행인지 기존 에이전트 기반 개선 루프인지를 자동 감지해 적절한 워크플로우를 실행합니다.
- 이중 루프 구조: 내부 루프는 실패 태스크의 일부를 대상으로 빠르게 반복하며 에이전트를 개선합니다. 외부 루프는 전체 벤치마크로 일반화 성능을 검증합니다. 빠른 실험과 안정적인 검증이 분리된 구조로, 과적합 없이 목표 성능에 수렴합니다.

실패 분석, 논문 검색, 코드 개선이 하나의 루프로 연결된다
Auto Research의 내부 루프는 다음의 모듈이 순서대로 연결되어 작동합니다. 각 모듈의 출력이 다음 모듈의 입력이 되고, 이 사이클이 자율적으로 반복됩니다.
- 실패 분석기 (Failure Analyzer): 에이전트가 실패한 태스크를 자동으로 분석해 실패 패턴과 근본 원인을 도출합니다. 어떤 상황에서 어떤 방식으로 실패했는지를 패턴별로 분류하고, 구조화된 문서로 저장합니다. 이 분석 문서가 다음 단계의 입력이 됩니다.
- 학술 문헌 연구기 (Literature Researcher): 실패 분석 결과를 바탕으로 관련 학술 논문을 자동으로 검색하고 분석합니다. 최신 연구만을 대상으로 검색하고, LLM이 논문을 읽고 현재 실패 패턴을 해결할 수 있는 아이디어를 추출합니다. 각 아이디어에는 출처 논문, 핵심 인사이트, 적용 방안이 함께 기록됩니다. 논문에서 추출한 아이디어가 직접 코드 개선으로 연결되는 구조입니다.
- 코드 개선기 (Code Improver): 실패 분석 문서와 논문 아이디어를 입력으로 받아 에이전트 소스 코드를 자동으로 수정합니다. LLM이 실패 패턴과 논문 아이디어를 종합해 코드 수정 계획을 수립하고, 의사결정 로직, 환경 상호작용, 에러 복구 메커니즘을 개선합니다.
- 샘플 평가기 (Sample Evaluator): 수정된 에이전트를 전체 벤치마크가 아닌 일부 샘플 태스크에 먼저 실행해 개선 여부를 빠르게 검증합니다. 전체 벤치마크를 돌리기 전 사전 검증 단계로, 개선이 확인된 경우에만 외부 루프의 전체 벤치마크 검증으로 넘어갑니다.
에이전트 하네싱(Agent Harness): 하나의 LLM이 여러 전문가 역할을 수행
이 시스템의 핵심 차별점 중 하나는 에이전트 하네싱입니다. 범용 LLM에게 단계별로 다른 역할과 제약을 부여해 특정 목적에 최적화된 행동을 유도합니다.
동일한 LLM이 각 단계마다 실패 분석가, 학술 연구자, 소프트웨어 엔지니어, 테스트 실행자, 평가 분석가라는 서로 다른 전문 역할을 수행합니다. 별도의 전문 모델 학습 없이 가능합니다. 각 세션이 독립적으로 실행되기 때문에 한 역할에서의 실수가 다른 역할로 전파되지 않습니다.
시스템 전체에 걸쳐 일관성을 유지하기 위한 전역 규칙이 존재하고, 각 단계별로 구체적인 목표와 제약이 개별적으로 전달됩니다. 루프가 진행되면서 에이전트의 개선 전략이 현재 상태에 맞게 자율적으로 조정됩니다.
세션이 끝나도 연구 맥락이 이어집니다
각 연구 단계는 독립적인 LLM 세션으로 실행됩니다. 세션이 독립적이면 이전 단계의 맥락이 끊기는 문제가 생깁니다. Enhans의 Auto Research 시스템은 텍스트 기반 컨텍스트 로그 파일을 매개로 이 문제를 해결합니다.
각 세션은 동일한 세 단계로 작동합니다. 시작 시 컨텍스트 로그 파일을 읽어 이전 세션들의 맥락을 파악합니다. 이후 자신의 역할에 해당하는 작업을 수행합니다. 완료 시에는 수행한 작업을 한 문단으로 압축해 로그 파일에 추가합니다. N번째 세션은 이 방식으로 1번째부터 N-1번째 세션까지의 누적 맥락을 확보합니다.
이 구조 덕분에 LLM의 컨텍스트 윈도우 제한을 우회하면서도 장기적 연구 맥락을 유지할 수 있습니다. 압축된 요약 형태로 정보를 전달하기 때문에 불필요한 토큰 소비도 방지합니다.
오케스트레이터와 에이전트 사이의 모든 통신은 파일 시스템을 매개로 이루어집니다. 모든 입출력이 파일로 남아 디버깅과 재현이 가능하고, 특정 단계에서 장애가 발생해도 해당 단계의 입력 파일이 남아 있어 재실행할 수 있습니다.

Auto Research AI가 효과적인 조건
성공과 실패를 자동으로 판정할 수 있는 객관적 지표가 있어야 루프가 작동합니다. 웹 에이전트 벤치마크, 코드 생성 평가, 자율 주행 시뮬레이션처럼 정량적 결과가 나오는 태스크가 여기에 해당합니다.
이 프레임워크는 도메인 비의존적으로 설계됐습니다. 대상 에이전트, 벤치마크, 평가 방식, 논문 검색 전략을 교체 가능한 모듈로 구성해 웹 에이전트, 자율 주행, 로봇 제어, 과학적 발견 등 다양한 영역에 동일한 구조를 적용할 수 있습니다.
주관적 판단이 필요한 영역에는 한계가 있습니다. 검증 기준 자체가 불명확한 태스크에서는 루프가 수렴하지 않습니다. 객관적 지표가 있는 영역에서 먼저 적용하고 점진적으로 확장하는 접근이 현실적입니다.
에이전트가 연구를 바꾸는 시대
Karpathy는 개인 SNS를 통해 Auto Research의 다음 목표를 이렇게 밝혔습니다. "단 한 명의 박사 과정 연구자를 모방하는 것이 목표가 아니라, 수많은 연구자들로 구성된 연구 커뮤니티 자체를 모방하는 것이 목표다.”
코딩이 에이전트로 넘어간 것처럼, 반복적 실험 설계와 문헌 탐색도 에이전트로 넘어갑니다. 실패 분석과 논문 검색이 자동화되면서, 연구자의 시간은 탐색 방향을 결정하는 판단에만 집중됩니다. 한 명의 연구자가 수십 개의 실험을 동시에 관리할 수 있게 됩니다.
그 변화는 이미 시작됐습니다. 에이전트가 탐색 공간을 채우는 동안, 연구자는 더 높은 수준의 질문에 집중할 수 있습니다.
in solving your problems with Enhans!
We'll contact you shortly!