

Ontology Lake: 데이터가 ‘의미를 알고 행동하는’ 구조로 전환되는 순간
온톨로지 시리즈 1편에서는 비정형 데이터가 어떻게 구조화되어 의미 있는 데이터 자산으로 전환되는지를 다뤘고, 2편에서는 그 온톨로지가 왜 LLM 기반 AI와 AI Agent를 실무 수준으로 끌어올리는 핵심 구조가 되는지 설명했습니다. 3편에서는 의미가 정리된 데이터와 온톨로지가 실제 업무 실행까지 어떻게 이어지는지, 그리고 이를 하나의 플랫폼에서 어떻게 구현할 수 있는지를 정리했습니다. 4편에서는 온톨로지와 데이터베이스 구조에 대한 논쟁을 통해, 엔터프라이즈 AI에서 중요한 것은 특정 저장 방식이 아니라 아키텍처 설계라는 점을 짚었습니다.
이번 글은 그 흐름을 이어, 온톨로지가 실제 데이터 플랫폼 위에서 어떻게 구현되며, 왜 이것이 AI 실행의 핵심 인프라로 이어지는지를 다루는 다섯 번째 글입니다.
데이터는 넘치는데, 왜 질문은 더 어려워지는가
엔터프라이즈 환경에서 데이터는 더 이상 부족한 자원이 아닙니다. 다양한 시스템에서 생성되는 로그와 이벤트, 트랜잭션 데이터는 지속적으로 축적되고 있으며, 조직은 그 어느 때보다 많은 데이터를 보유하고 있습니다. 그러나 데이터의 양이 증가할수록 질문에 답하기는 더 어려워지고 있으며, 이는 단순한 데이터 처리 능력의 문제가 아니라 데이터가 갖는 의미를 시스템이 이해하지 못하는 구조적 한계에서 비롯됩니다.
다음과 같은 질문들은 여전히 시스템이 아니라 사람이 해결하고 있습니다.
- 이 데이터는 무엇을 의미하는가
- 이 데이터와 저 데이터는 어떤 관계인가
- 이 결과를 비즈니스 맥락에서 어떻게 해석해야 하는가
데이터는 존재하지만, 의미는 시스템 바깥에 존재하는 구조입니다. 이로 인해 분석 속도는 느려지고, 조직마다 해석이 달라지며, AI를 도입하더라도 실제 실행으로 이어지지 않는 문제가 반복됩니다.
결국 데이터 문제의 본질은 데이터의 양이 아니라, 데이터에 의미가 내장되어 있지 않다는 점입니다.
현재 데이터 아키텍처가 해결하지 못한 영역
기존 데이터 아키텍처는 이 문제를 완전히 해결하지 못한 채 서로 다른 방식으로 이를 보완해 왔습니다.

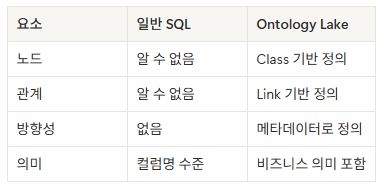
관계형 시스템은 숫자와 집계에는 강하지만 의미를 표현하지 못하고, 그래프 시스템은 관계를 잘 표현하지만 엔터프라이즈 환경의 핵심 요구사항을 모두 만족시키기 어렵습니다.
이로 인해 많은 조직은 데이터 저장, 분석, 관계 탐색을 각각 다른 시스템에 분리하여 구성하고 있으며, 그 결과 데이터는 존재하지만 의미와 실행은 연결되지 않은 상태로 남게 됩니다.
Ontology Lake: 데이터 위에 의미를 내장하는 구조
Ontology Lake는 이 단절을 해소하기 위해 데이터 위에 의미 계층을 명시적으로 설계하는 방식입니다. COS Ontology Lake는 비즈니스 도메인의 개념과 관계를 메타데이터로 정의하고, 이를 실제 데이터와 결합하여 하나의 통합된 구조로 만듭니다.
핵심 구조는 다음과 같이 정리할 수 있습니다.
- Class: 비즈니스 엔티티 정의
- Property: 속성과 속성의 의미 정의
- Link: 엔티티 간 관계 정의
이 구조는 단순한 데이터 모델링이 아니라, 조직의 비즈니스 언어를 시스템이 이해할 수 있는 형태로 변환하는 과정입니다. 이 메타데이터는 SQL 기반 데이터와 결합되어 동작하며, 기존 인프라의 성능과 확장성을 유지하면서도 데이터 간의 관계를 그래프 형태로 표현할 수 있도록 합니다 .
또한 데이터는 다음과 같은 구조로 운영됩니다.
[Query Interface (SQL / Cypher / Natural Language)]
↓
[Semantic Layer (Ontology)]
↓
[SQL Engine Layer]
↓
[Result: Table + Graph]
이 구조에서 온톨로지는 단순한 설명 레이어가 아니라, 데이터 해석과 실행을 연결하는 핵심 계층으로 작동합니다.
의미가 쿼리를 만들고, 결과를 완성한다
Ontology Lake에서는 쿼리 방식 자체가 바뀝니다. 사용자는 더 이상 테이블 구조와 JOIN 조건을 직접 설계하지 않고, 비즈니스 관계를 중심으로 질의를 구성합니다.
예를 들어 Person과 Company의 관계를 조회하는 경우, 시스템은 다음과 같은 과정을 자동으로 수행합니다.
- Class 메타데이터를 기반으로 테이블 매핑
- Link 정보를 기반으로 JOIN 경로 탐색
- 최적화된 SQL 생성 및 실행
이 과정은 Semantic Query Compiler가 담당하며, 사용자의 의도를 데이터 구조로 변환합니다 .
또한 결과 역시 단순한 테이블로 끝나지 않습니다.
쿼리 결과는 온톨로지 메타데이터를 기반으로 그래프 구조로 재해석되며, 사용자가 모든 관계를 명시하지 않아도 시스템이 이를 보완하여 일관된 결과를 제공합니다.
데이터에서 실행으로: AI가 작동하는 구조
이 구조는 AI와 결합될 때 그 효과가 더욱 분명해집니다. 기존 환경에서는 AI가 데이터를 읽고 요약하는 수준에 머무르는 경우가 많았지만, 데이터의 의미 구조를 이해하지 못하기 때문에 실제 업무 실행으로 이어지는 데에는 한계가 있었습니다.
Ontology Lake가 도입되면 다음과 같은 흐름이 가능해집니다.
자연어 요청
→ 의미 구조 해석 (Ontology)
→ 쿼리 생성 (SQL / Cypher)
→ 결과 반환 (의미 포함)
→ 실행 가능한 형태로 활용
이 과정에서 AI는 데이터를 단순히 해석하는 도구를 넘어, 비즈니스 맥락을 이해하고 실제 업무 흐름 안에서 활용될 수 있는 결과를 만들어내는 주체로 전환됩니다.
데이터는 더 이상 조회 대상이 아니라, 실행을 가능하게 하는 인프라로 변화합니다.
결론: 데이터 플랫폼은 ‘의미 인프라’로 진화한다
데이터 플랫폼의 진화 방향은 명확합니다. 저장과 처리 중심의 구조를 넘어, 데이터에 의미를 부여하고 그 의미가 쿼리와 실행을 이끄는 구조로 이동하고 있습니다.
Ontology Lake는 이 변화의 중심에 있습니다. 데이터에 의미를 내장하고, 그 의미를 기반으로 질의와 해석, 그리고 실행까지 연결하는 구조가 만들어지는 순간, 데이터는 조직의 의사결정과 실행을 직접적으로 움직이는 기반으로 전환됩니다.
데이터가 많아지는 시대에서 경쟁력은 데이터의 양이 아니라, 데이터를 얼마나 의미 있게 연결하고 활용할 수 있는지에 달려 있습니다. 그리고 그 출발점이 바로 Ontology Lake입니다.
온톨로지 기반 데이터 아키텍처를 실제 기업 환경에 어떻게 설계하고 적용할 수 있는지, 보다 구체적인 구조나 구현 방식이 궁금하다면 문의하세요.
문의하기
in solving your problems with Enhans!
We'll contact you shortly!