
.png)
온톨로지 시리즈의 1편에서 우리는 비정형 데이터가 어떻게 온톨로지로 “정형화”되는지 다뤘습니다.
이번 2편에서는 한 단계 더 들어가서, 온톨로지가 왜 LLM 기반 AI를 실무 수준으로 끌어올리는 핵심 구조가 되는지 설명합니다.
1. LLM의 시대, 그리고 실무에서 드러나는 한계
ChatGPT, Claude, Gemini의 등장 이후 AI 활용은 급격히 확산됐습니다. 자연어로 질문하고 결과를 받는 경험은 이제 대부분의 업무 환경에서 기본이 됐습니다. LLM의 강점은 분명합니다. 하나의 모델이 요약, 번역, 질의응답, 분류 등 다양한 언어 작업을 처리하고, 별도의 학습 파이프라인 없이 API로 즉시 적용할 수 있습니다.
문제는 운영 단계에서 발생합니다. LLM은 텍스트를 매우 그럴듯하게 답변을 생성하지만, 그 결과가 사실인지, 수치적으로 정합한지, 회사 규칙을 지켰는지를 보장하지 않습니다. 이때 나타나는 대표적인 실패가 할루시네이션입니다.
특히 커머스, 의료, 법률처럼 정확한 수치, 정보, 일관된 판단이 필요한 도메인에서는, 이 약점이 곧바로 실무 적용의 한계로 이어집니다.
2. LLM의 한계를 넘어서는 열쇠: 지식의 구조화

LLM이 실제 실무에서 '에이전트(Agent)'로서 제 역할을 다하기 위해서는 단순한 언어 생성을 넘어 팀의 업무 노하우와 높은 수준의 데이터 신뢰도를 갖춰야 합니다.
AI가 실무를 수행하도록 만들기 위해서는 다음과 같은 요소가 필수적입니다:
- 높은 정확도와 신뢰성 있는 데이터 확보.
- LLM이 이해하고 구조화할 수 있는 형태로의 데이터 정제.
- 회사별 업무 방식, 규칙, 용어가 반영된 맞춤형 지식 베이스 구축.
- 지속적인 피드백 학습(Feedback Loop)과 인간 검증(Human-in-the-loop)을 통한 품질 개선.
필수적인 요소들을 충족시키고 AI에게 '세상의 맥락'을 가르쳐주는 기술이 바로 온톨로지(Ontology)입니다.
3. 온톨로지: 데이터를 지식 구조로 올리는 레이어
온톨로지라는 용어는 고대 그리스 철학자 아리스토텔레스의 '존재론'에서 유래했습니다. 근원적인 질문에 대한 답을 찾는 철학적 개념이 AI시대에 데이터 처리 시스템으로 확장된 것이 온톨로지입니다.
기술적으로 온톨로지는 다음을 명시합니다.
- 어떤 “대상(개체, Entity)”이 존재하는지
- 그 대상이 어떤 “속성(Property)”을 갖는지
- 대상과 대상 사이의 “관계(Relationship)”가 무엇인지
DB와 스키마가 “값을 저장”하는 구조라면, 온톨로지는 “값의 의미와 연결”을 정의합니다. 이 차이가 중요한 이유는, LLM이 관계와 제약을 명시적으로 제공받을 때 훨씬 안정적으로 추론하기 때문입니다.
예를 들어 “리뷰 평점이 낮아진 이유”를 묻는다고 했을 때, LLM은 그럴듯하지만 실제 원인과 다른 할루시네이션을 생성할 수 있습니다. 하지만 온톨로지를 통해 “상품–프로모션–배송–CS–리뷰–재구매” 단계를 연결하고, 각 단계의 속성과 규칙을 정의하고 있다면, 실무에서 바로 응용할 수 있는 근거 기반 인사이트로 답변이 바뀌게 됩니다.
4. 실무에서의 차이: 온톨로지 vs. RAG(검색 증강 생성)
현재 AI 분야에서 유행하는 RAG(Retrieval-Augmented Generation) 방식은 질문과 유사한 문서를 벡터 DB에서 찾아 LLM이 답변하게 하는 하이브리드 방식입니다. 하지만 RAG는 확률적 유사도이기에 정확한 숫자가 중요한 커머스 환경에서 명확한 한계를 보입니다.
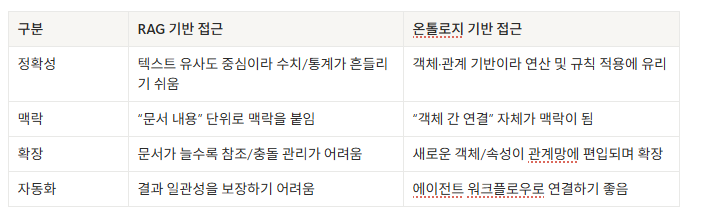
실제 인핸스의 CommerceOS를 통해 "이번 달 매출과 리뷰 추이를 분석해줘"라는 질문을 던졌을 때, RAG 기반 AI는 대략적인 금액만 전달하지만, 온톨로지 기반 AI는 정확한 합계 금액(원 단위), 일자별 추이, 프로모션 영향도 등 깊이 있는 인사이트를 정확한 수치와 함께 산출해냅니다.
5. Enhans 온톨로지의 4가지 구성 요소
Enhans 온톨로지는 크게 네 가지 개념을 중심으로 구축됩니다:
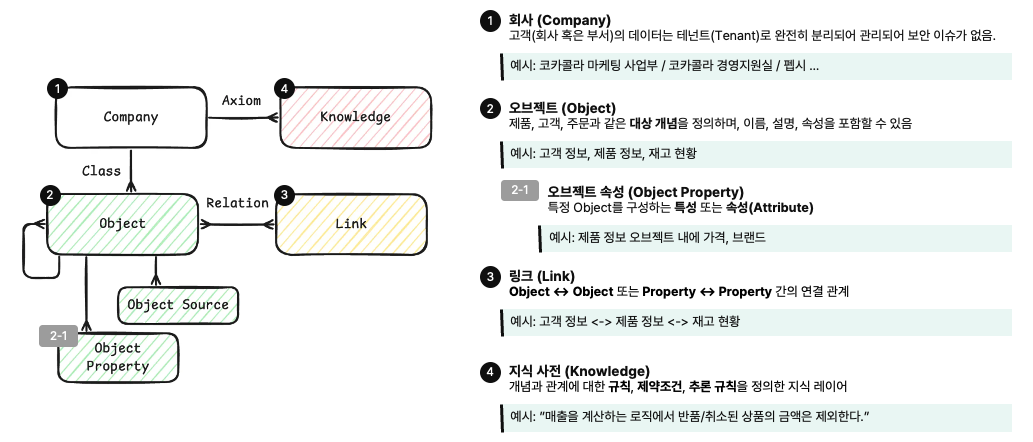
- 오브젝트 (Object): 제품, 고객, 주문과 같은 대상 개념을 정의하며, 이름, 설명, 속성(Attribute)을 포함합니다.
- 속성 (Property):• 오브젝트가 가지는 구체적인 특징과 상태를 정의합니다. 가격, 수량, 카테고리, 생성일, 상태값과 같은 정형 데이터뿐 아니라, LLM을 통해 생성된 의미적 설명, 요약, 분류 결과와 같은 비정형·파생 속성도 포함합니다. 이를 통해 동일한 오브젝트라도 분석 목적이나 컨텍스트에 따라 다층적인 해석과 활용이 가능해집니다.
- 링크 (Link): 오브젝트 간의 연결 관계를 정의하여 숨겨진 맥락과 의미를 연결합니다. 예를 들어 '매출-프로모션-리뷰' 사이의 파생된 관계를 찾아냅니다.
- 지식 사전 (Knowledge): 비즈니스 로직, 제약 조건, 추론 규칙을 담고 있습니다. "매출 계산 시 취소 상품 금액은 제외한다"와 같은 기업 고유의 규칙이 여기에 포함됩니다.
특히 인핸스는 고객사의 데이터를 테넌트(Tenant) 단위로 완전히 분리하여 관리하므로 보안 이슈 없이 기업별 맞춤 지식 그래프를 구축할 수 있다는 강력한 장점이 있습니다.
6. 엔터프라이즈 환경에 도입 가능한 AI의 핵심은 “프레임워크”
LLM의 성능이 좋아질수록, 오히려 더 중요한 질문은 이것이 됩니다.
“이 모델은 무엇을 참고하고, 어떤 규칙 위에서 판단하는가?”
방대한 데이터 더미 속에서 단순히 일부만 보거나 경험에 의존해 의사결정을 내리던 시대는 끝났습니다. 온톨로지는 흩어진 데이터를 하나의 지식 네트워크로 엮어줌으로써, AI가 단순한 도구를 넘어 비즈니스의 핵심 파트너로 거듭나게 하는 필수적인 엔진입니다.
온톨로지는 마치 거대한 도서관의 엉망진창인 책들을 주제별, 저자별, 내용별로 꼼꼼하게 분류하고 서로 연관된 책들을 실로 연결해둔 정교한 지도와 같습니다. 길을 잃기 쉬운 지식의 바다에서 AI가 가장 정확하고 빠른 길을 찾을 수 있도록 돕는 나침반이 되어줄 것입니다.
본 글에서 온톨로지를 활용한 “AI 지식 구조화”를 다뤘다면, 3편은 그 구조 위에서 온톨로지를 통해 “업무가 실행되는 방식”에 대한 이야기를 인핸스의 CommerceOS 사례를 통해 공유하겠습니다.
in solving your problems with Enhans!
We'll contact you shortly!