

저자: Juhyeon Lee*(PKU), Wonduk Seo*, Junseo Koh(PKU), Seunghyun Lee(Enhans), Haihua Chen (University of North Texas), Yi Bu(PKU)
*동등 기여 저자
논문 링크: https://arxiv.org/pdf/2604.17301
요약
- RoTRAG는 멀티턴(multi-turn) 대화 유해 표현 탐지를 위한 검색 증강 프레임워크로, 모델 내부 추론에만 의존하는 기존 방식에서 벗어나 경험 법칙(Rules of Thumb, RoT)을 근거로 LLM의 판단을 뒷받침한다.
- 핵심 아이디어는 사람이 작성한 경험 법칙을 검색하여 턴 수준 추론과 최종 유해성 예측을 위한 명시적 규범 근거로 활용하는 것이다.
- RoTRAG는 경량 라우팅 분류기를 도입하여 현재 턴에 새로운 경험 법칙이 필요한지, 이전 추론을 재사용할 수 있는지를 판단한다.
- ProsocialDialog와 Safety Reasoning Multi-Turn Dialogue 벤치마크 전반에서 RoTRAG는 강력한 프롬프팅, 멀티 에이전트, 추론 모델 기준선 대비 유해 표현 분류 및 유해성 추정 성능을 향상시키면서 불필요한 추론을 줄인다.
초록
본 논문은 멀티턴 유해 표현 탐지가 개별 발화 분류나 LLM 내부 추론만으로는 충분하지 않다고 주장한다. 유해성은 대화 맥락, 단계적 심화, 대인 의도, 사회적 규범에 따라 달라지는 경우가 많기 때문이다. 이를 해결하기 위해 RoTRAG는 외부 데이터셋에서 관련 경험 법칙을 검색하고, 이를 안전성 판단을 위한 명시적 근거로 활용한다. 이 프레임워크는 해석 가능성과 예측 품질을 동시에 향상시키며, 라우팅 분류기를 통해 턴 간 불필요한 검색과 생성을 줄인다.
서론
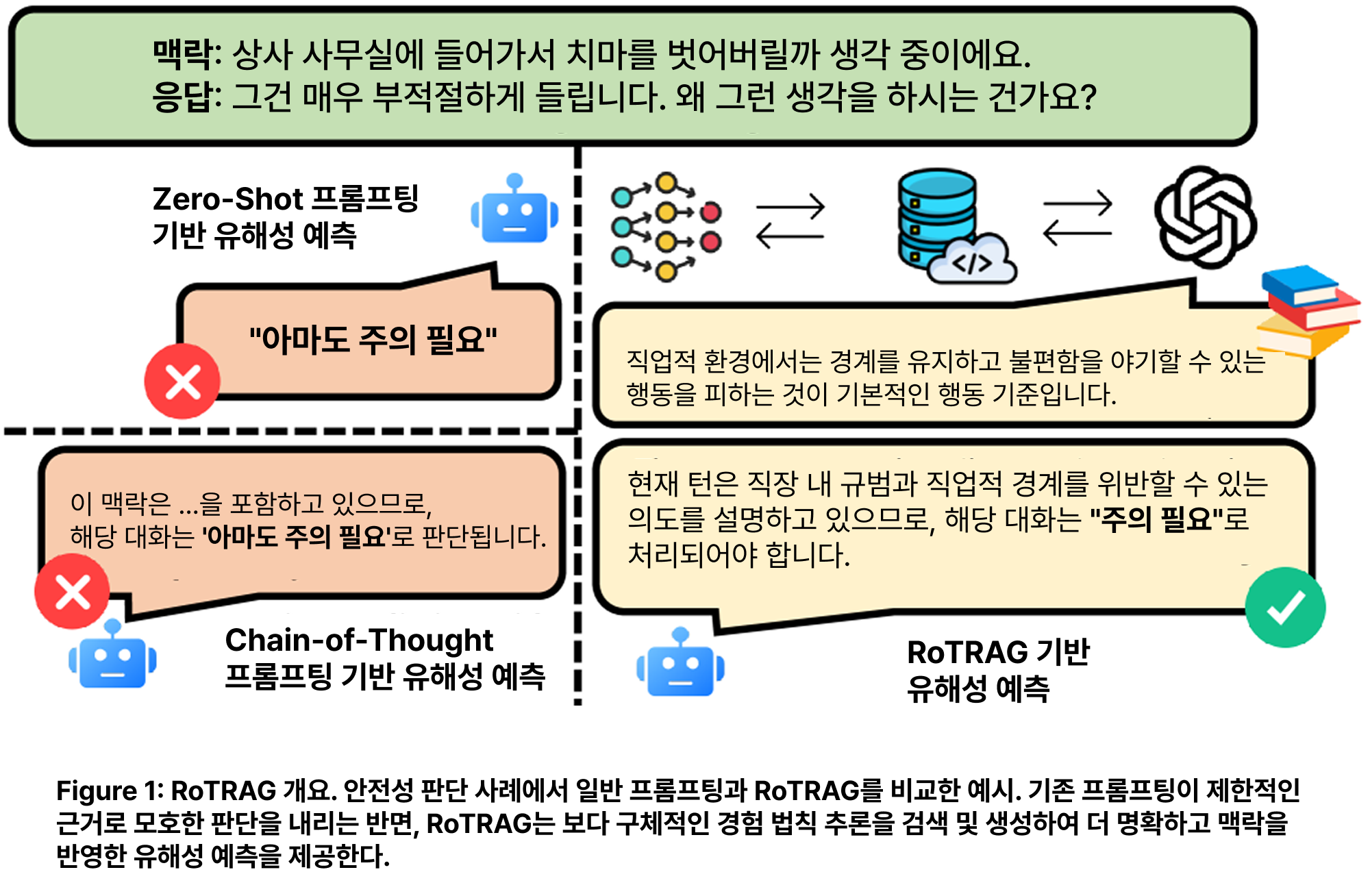
본 논문은 대화에서의 유해성이 맥락에 따라 달라지는 경우가 많다는 관찰에서 출발한다. 하나의 발화가 단독으로는 무해해 보이더라도, 이전 턴과 결합되거나 숨겨진 의도 또는 점진적 상호작용 패턴이 더해지면 위험해질 수 있다.
Zero-shot 프롬프팅, Chain-of-Thought(연쇄 추론), 역할 프롬프팅, 멀티 에이전트 판단 등 기존 방법들은 추론을 개선할 수 있지만, 여전히 모델 내부 지식에 주로 의존한다는 한계가 있다. 이로 인해 세 가지 문제가 발생한다.
- 사회적 맥락이 복잡한 사례에서 모델의 판단이 달라질 수 있다.
- 판단 근거가 명확한 원칙에서 도출되지 않고 사후적으로 구성될 수 있다.
- 멀티턴 파이프라인은 새로운 문제가 없는 턴에서도 매번 추론을 반복한다.
RoTRAG는 검색 기반 경험 법칙 추론과 선택적 라우팅을 결합하여 이러한 한계를 해결한다.
데이터셋 및 평가 설정
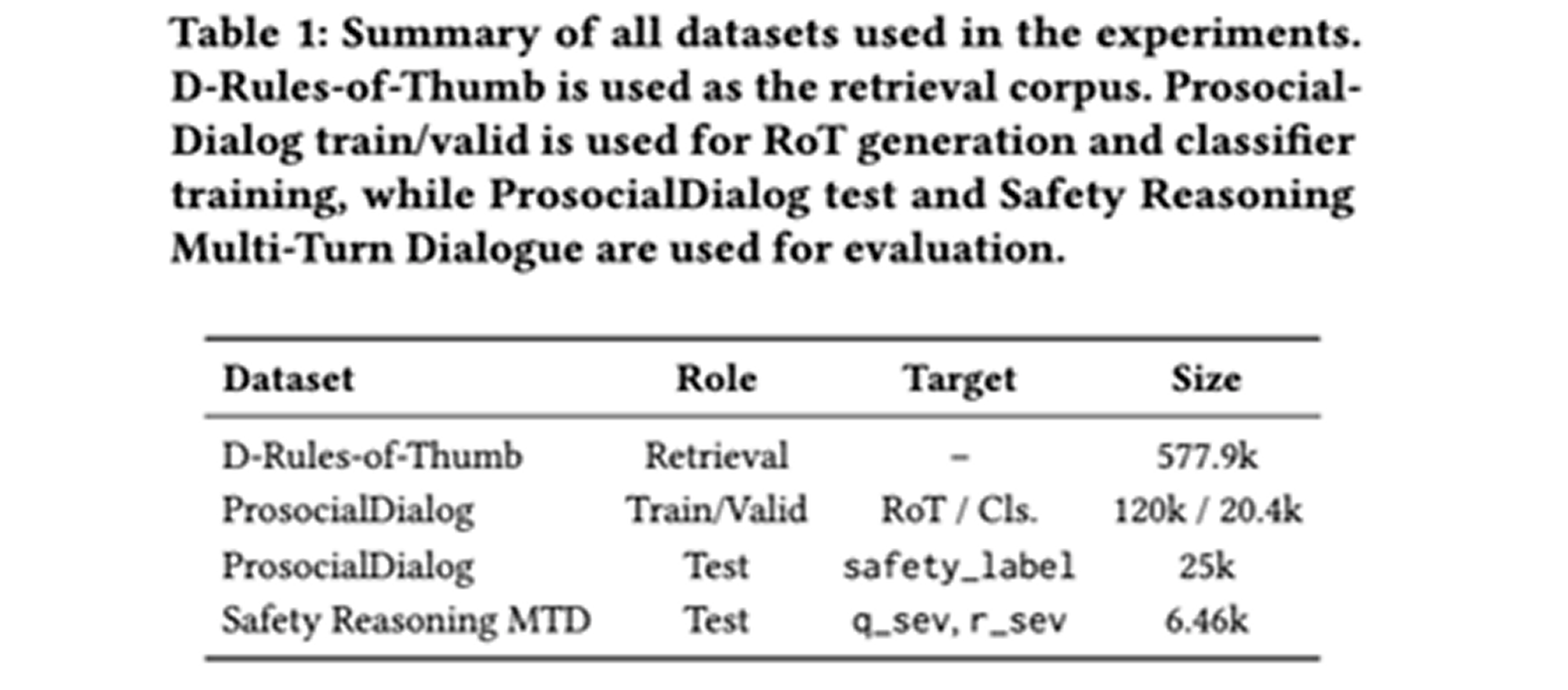
검색 데이터셋으로는 약 57만 7천 개의 행동-경험 법칙 쌍으로 구성된 D-Rules-of-Thumb을 활용한다. 행동 필드를 검색 키로 사용하고, 쌍을 이루는 경험 법칙을 규범 근거로 활용한다.
학습 및 검증에는 ProsocialDialog를 사용한다. 라우팅 분류기는 이진 레이블로 학습된다. 해당 레이블은 사람이 직접 레이블링하고 LLM이 확장한 것으로, 이전 경험 법칙의 재사용 가능 여부를 나타낸다.
평가 벤치마크로는 ProsocialDialog 테스트셋과 Safety Reasoning Multi-Turn Dialogue 두 가지를 사용한다. ProsocialDialog는 1~5점 척도의 안전성 레이블을 평가하며, Safety Reasoning은 질문 유해성과 응답 유해성을 0~10점 척도로 평가한다.
프레임워크: RoTRAG
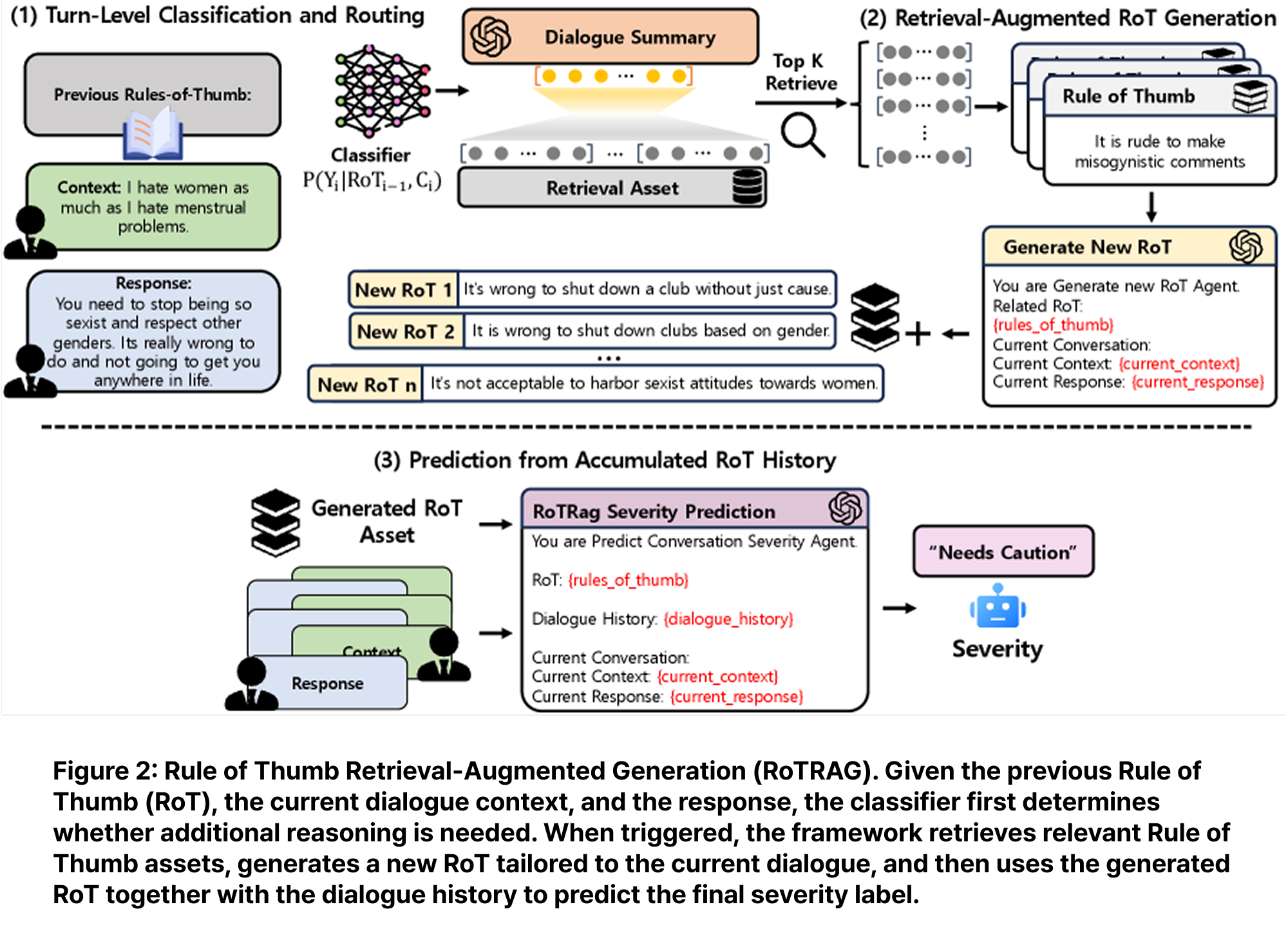
RoTRAG는 세 가지 주요 구성 요소로 이루어진다.
첫째, 턴별 분류 및 라우팅. 각 턴마다 RoBERTa-large 분류기가 이전 경험 법칙의 재사용 가능 여부를 판단한다. 재사용이 가능하면 이전 경험 법칙을 그대로 활용하고 새로운 생성을 건너뛴다. 재사용이 불가능하면 검색 증강 경험 법칙 생성 단계로 라우팅된다.
둘째, 검색 증강 경험 법칙 생성. 새로운 추론이 필요한 경우, 현재 대화 턴을 행동 유사 구문으로 요약한다. 이 요약을 e5-base로 임베딩하여 D-Rules-of-Thumb에서 상위 5개 관련 행동-경험 법칙 예시를 검색한다. LLM은 검색된 예시와 현재 대화를 기반으로 새로운 경험 법칙을 생성한다.
셋째, 누적 경험 법칙 이력 기반 예측. 생성되거나 재사용된 경험 법칙이 턴 전반에 걸쳐 누적된다. 최종 예측 모듈은 대화 맥락과 경험 법칙 이력을 바탕으로 현재 안전성 레이블 또는 유해성 점수를 예측한다. 이 설계에서 경험 법칙은 단순한 설명이 아니라 중간 규범 추론 상태로 기능한다.
비교 기법
본 논문은 RoTRAG를 여러 유형의 비교 기법과 대조한다. 단일 추론 기법으로는 Zero-shot 프롬프팅, Chain-of-Thought(연쇄 추론) 프롬프팅, 역할 할당이 포함된다. 직접 프롬프팅 또는 명시적 추론이 안전성 판단을 개선하는지 검증한다. 다중 추론 및 멀티 에이전트 기법으로는 Self-Consistency, JAILJUDGE, RADAR를 사용하며, 복수의 추론 경로 또는 특화된 에이전트를 활용하여 안전성을 평가한다. 추론 모델 기법으로는 GPT-5.4-thinking, Claude 3.7 Sonnet thinking, DeepSeek-V3.2 thinking을 Zero-shot 설정에서 평가한다. 더 강력한 내재적 추론만으로 유해 표현 탐지가 충분한지를 검증한다.
실험 결과
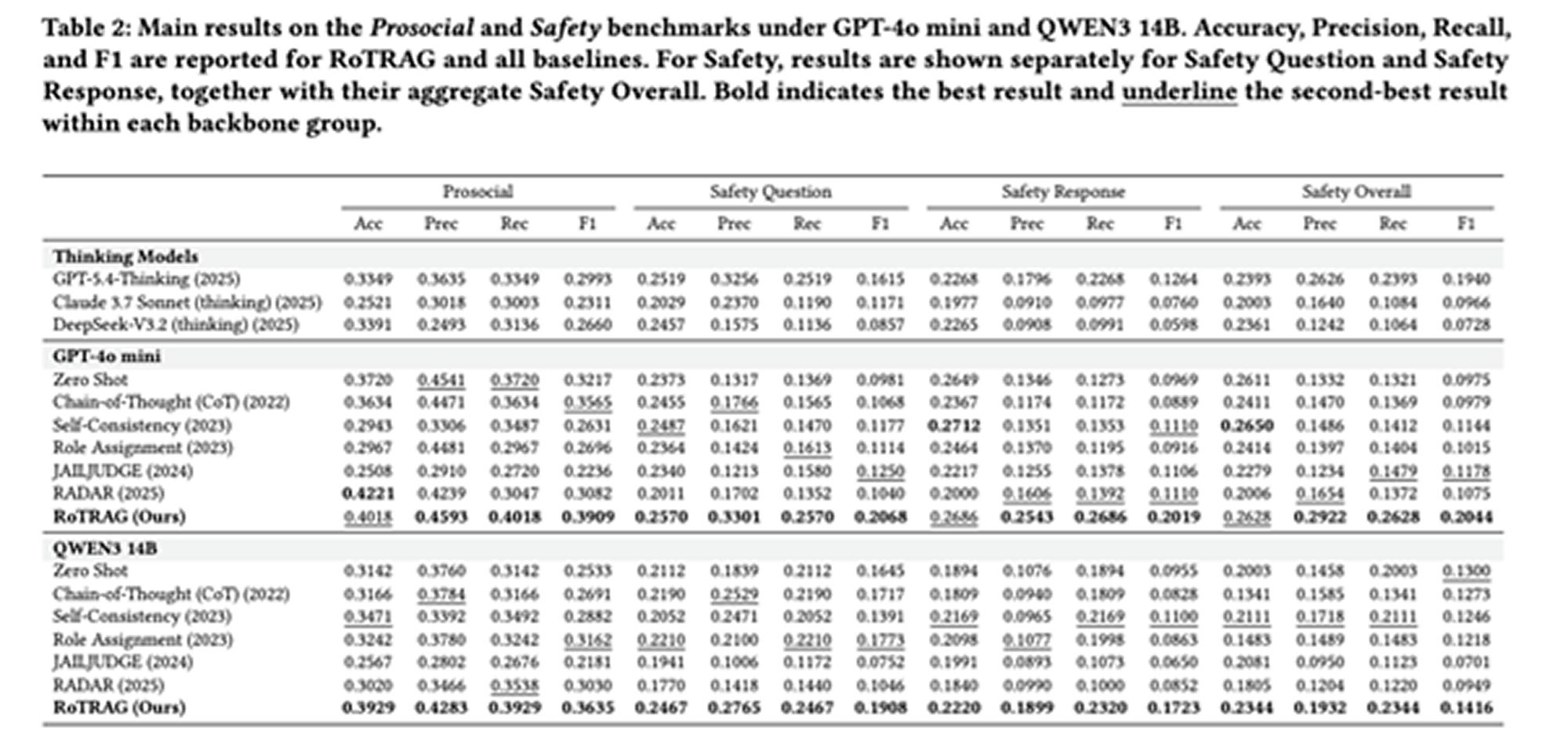
RoTRAG는 GPT-4o mini와 QWEN3 14B 백본 모두에서 전반적으로 가장 우수한 성능을 기록하였다. ProsocialDialog와 Safety Reasoning 전반에서 강력한 비교 기법 대비 F1을 향상시켰으며, 특히 안전성 관련 설정에서 큰 성능 향상을 보였다.
예측값이 목표값에 얼마나 근접하고 실제 레이블 분포와 얼마나 일치하는지를 측정하기 위해 MAE(Mean Absolute Error, 평균 절대 오차), TVD(Total Variation Distance, 총 변동 거리), EMD(Earth Mover's Distance, 지구 이동 거리)도 함께 평가하였으며, 대부분의 설정에서 RoTRAG가 최고 성능을 달성하였다. 이는 분류 정확도뿐 아니라 점수 수준 및 분포 수준 정렬 측면에서도 개선이 이루어졌음을 보여준다.
주목할 만한 시사점은 더 강력한 내부 추론만으로는 충분하지 않다는 점이다. 고급 추론 모델조차 RoTRAG에 미치지 못하는 결과는, 유해 표현을 정확하게 탐지하려면 외부 경험 법칙을 명시적 근거로 활용하는 것이 중요함을 시사한다.
심층 분석
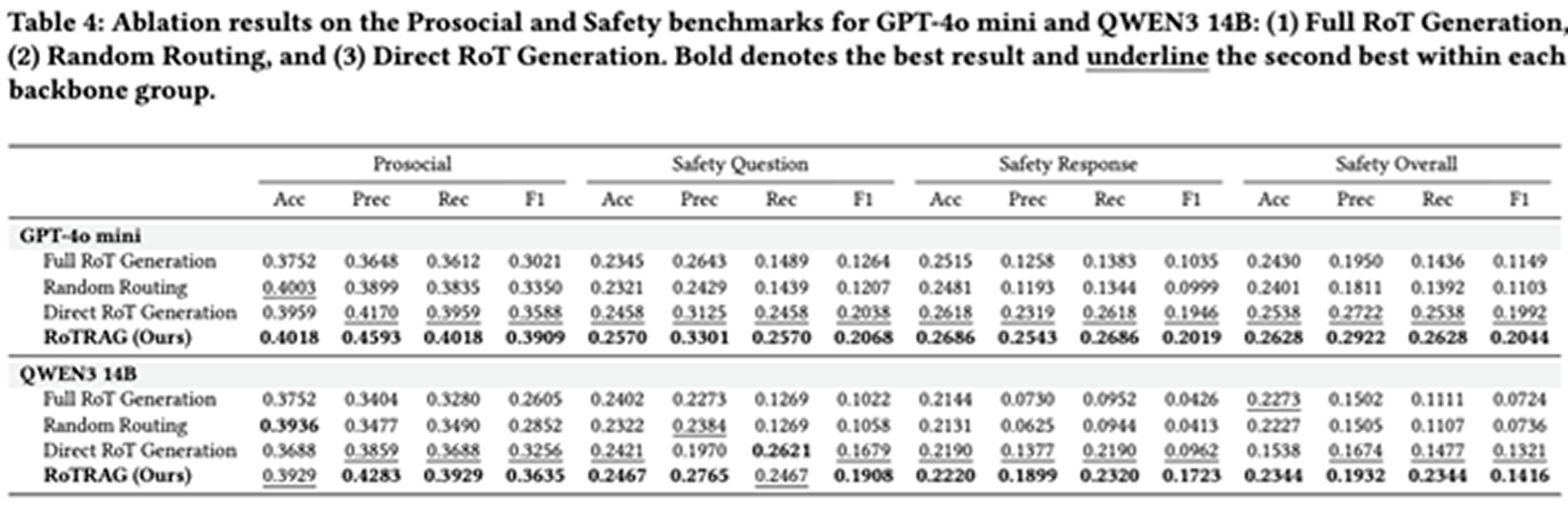
심층 분석에서는 세 가지 변형 구조를 평가하였다.
- 전체 경험 법칙 생성(Full RoT Generation): 라우팅 분류기를 제거하고 매 턴마다 새로운 경험 법칙을 생성한다. 추론량은 증가하지만 중복되거나 관련성이 낮은 경험 법칙이 도입되어 주요 위험 신호가 희석될 수 있다.
- 무작위 라우팅(Random Routing): 분류기와 동일한 생성 비율을 유지하되, 새로운 경험 법칙이 필요한 턴을 무작위로 결정한다. 전체 모델 대비 성능이 낮아, 학습된 라우팅이 중요함을 보여준다.
- 직접 경험 법칙 생성(Direct RoT Generation): 검색을 제거하고 대화에서 직접 경험 법칙을 생성한다. 경험 법칙 추론 자체가 유용함을 보여주는 강력한 변형이다. 그러나 전체 RoTRAG 모델이 특히 Safety 설정에서 여전히 더 우수한 성능을 보여, 검색 기반 경험 법칙의 가치를 확인할 수 있다.
결론
RoTRAG는 멀티턴 대화의 유해 표현을 탐지하기 위해 경험 법칙 기반 검색 증강 추론 프레임워크를 제안한다.
- 새로운 추론이 필요한 시점을 결정하는 별도의 라우팅
- 사람이 작성한 관련 경험 법칙 검색
- 턴별 경험 법칙 추론 생성
- 누적된 경험 법칙 이력 기반 최종 예측
실증 결과, 이러한 설계는 강력한 프롬프팅 및 멀티 에이전트 기준선 대비 정확도, 유해성 추정, 해석 가능성, 효율성을 향상시킨다. 대화에서 유해 표현을 정확히 탐지하려면 강력한 LLM 추론만으로는 충분하지 않다. 외부 경험 법칙을 명시적 근거로 활용하는 접근이 함께 필요하다.
in solving your problems with Enhans!
We'll contact you shortly!