

Author: WondukSeo, Wonseok Choi, Junseo Koh, Juhyeon Lee, Hyunjin An, Minhyeong Yu, JianPark, Qingshan Zhou, Seunghyun Lee, Yi Bu
Enhans, Peking University, Fudan University
Pre-print Version,arXiv:2601.21700v2
Paper Link: https://arxiv.org/pdf/2601.21700
TL;DR
1. OG-MAR proposes an ontology-guided, demographically grounded multi-agent inference pipeline for culturally aligned decisions, addressing “culture-default” bias from web-skewed pretraining.
2. The key move is to treat cultural values as a structured graph (a global cultural ontology built from competency questions) rather than independent snippets,improving consistency and interpretability.
3. Atinference time, OG-MAR retrieves (i) ontology-consistent relation triples and(ii) demographically similar WVS profiles, instantiates multiple value-persona agents, then uses a judgment agent that prioritizes evidence + ontology consistency + demographic proximity.
4. Across six regional survey benchmarks and four LLM backbones, OG-MAR improves average accuracy over strong baselines (zero-shot, role prompting, self-consistency,debate, ValuesRAG) and yields more transparent reasoning traces.
Abstract
LLMs are increasingly used for culturally sensitive decisions, but are often misaligned due to skewed pretraining data and lack of explicit value structure. OG-MAR addresses this by(1) summarizing respondent-specific values from WVS under a fixed taxonomy, (2)constructing a global cultural ontology via competency-question-driven relation elicitation, and (3) performing ontology + demographic retrieval to drive multi-persona simulation and evidence-first adjudication for culturally aligned predictions.
Introduction
The paper argues that many “cultural steering” methods remain brittle because they either:
- rely on implicit cultural assumptions (prompt-sensitive),
- treat values as independent, unstructured signals (missing cross-topic dependencies),
- or use multi-agent aggregation without an explicit value structure, reducing interpretability.
OG-MAR reframes cultural alignment as structured cultural knowledge + demographic grounding + multi-agent simulation, where an ontology provides the “skeleton” for how values relate, and real survey profiles provide “ground truth-ish” anchors for personas.
Datasets and Evaluation Setting
Datasets
Retrieval corpus: World Values Survey (WVS), using a Wave-7(2017–2022) subset as described in the project page (≈94,728 respondents; 239 value questions after preprocessing).
Test benchmarks (regional surveys):
EVS (Europe), GSS (U.S.), CGSS(China), ISD (India), LAPOP (Latin America), Afrobarometer (Africa).
Task +Metrics
Items are cast into a binary decision setup and evaluated primarily with accuracy; for ordinal items, the paper also reports MAE after binarization/label mapping. (described in your excerpt; also reflected in the project page results section)
Models /Components
- Generation backbones (persona + judge): GPT-4o mini, Gemini 2.5 Flash Lite,Qwen 2.5, EXAONE 3.5 (temperature=0).
- Embedding retrieval: E5-base embeddings for dense retrieval (demographics +ontology triples). (in your provided text and reflected on the project page)
- Topic classification: DeBERTa-v2-xx large fine-tuned on WVS (12-domain supervision).
Framework: OG-MAR
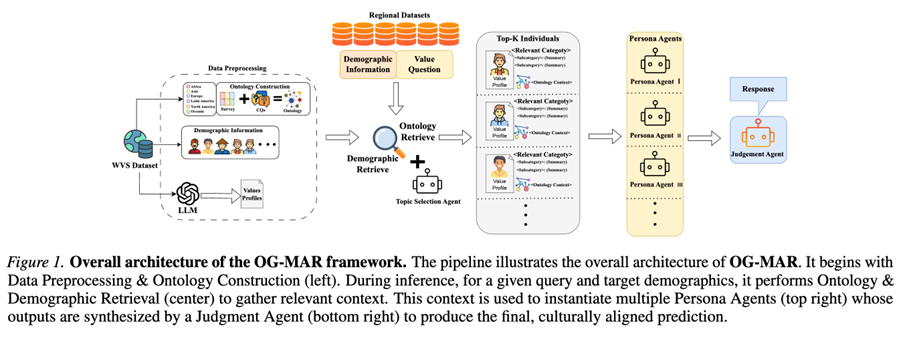
OG-MAR turns “values” into (A)structured profiles and (B) structured relations, then uses them to drive multi-persona reasoning with a constrained, evidence-first judge.
Stage 1. Data preprocessing: Topic-aware value summaries Each WVS respondent’s raw answers are summarized into a fixed taxonomy (12 domains, 76 fine-grained categories), producing a structured value profile per individual.
Stage 2. Ontology construction: CQ-guided relation elicitation + human consolidation
- Experts write Competency Questions (CQs) that probe relations between parent value domains.
- An LLM proposes natural-language “triples” (class A, relation text, class B) under cultural conditioning (profiles sampled across world regions).
- Humans review/edit/filter to obtain a curated ontology (reported as 76 classes with ~150 pairs of object properties).
Stage 3. Inference pipeline:retrieval → personas → constrained meta-adjudication
- Topic selection: pick top-k domains, then top-p fine-grained categories relevant to the query.
- Ontology retrieval: retrieve top-M ontology triples constrained to the selected categories.
- Demographic retrieval: retrieve top-K demographically similar individuals (default K=5).
- Persona simulation:instantiate one persona agent per retrieved individual; each produces an answer+ reasoning trace grounded in (ontology triples + that individual’s value summaries).
- Judgment agent:aggregates persona outputs using an “evidence & consistency first” protocol(only using votes as a fallback under near-ties, and breaking ties via demographic proximity).

Baselines
The main comparisons include:
- Zero-shot
- Role assignment / cultural prompting
- Self-consistency (sample-and-vote)
- Debate-style multi-agent
- ValuesRAG (retrieval of survey evidence without ontology structure)
Experimental Results
Main Results
OG-MAR achieves the best (or near-best) average accuracy across six regions and four backbones, with reported averages approximately:
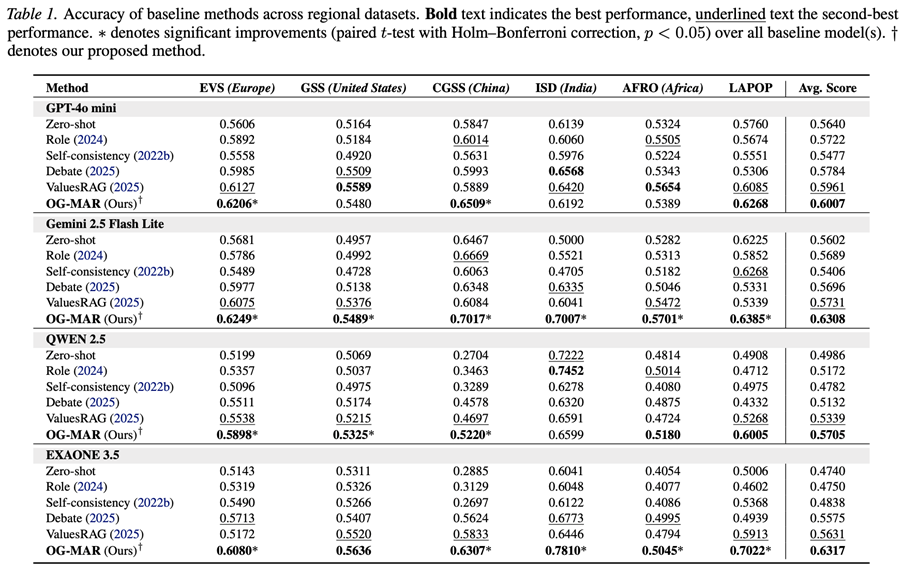
A recurring takeaway is that ValuesRAG is strong, but OG-MAR often surpasses it by adding structured relations (ontology) + persona diversity + consistency-aware adjudication,especially on harder distribution-shift settings (e.g., CGSS/ISD in the table).
Ablation Studies
- # Retrieved personas (K ∈{1,3,5,10}): best overall at K=5, while K=10 degrades (noise /conflicting evidence).
- Value-Inference Variant vs OG-MAR: replacing K personas with a single “infer target value profile” agent is generally weaker for most models/datasets, suggesting explicit multi-persona evidence helps the judge.
- Single-judge variant vs OG-MAR: skipping persona simulation and having one judge directly answer with the same context reduces accuracy, often substantially (especially for the open-source backbones).
Conclusion
OG-MAR’s main contribution is a structured cultural reasoning stack:
- WVS-based demographic grounding (who are we simulating?),
- CQ-built cultural ontology (how do values relate?),
- multi-persona simulation + constrained adjudication (how do we aggregate evidence robustly?).
Empirically, this combination improves cultural alignment robustness across regions and backbones, while making the decision process more inspectable than unstructured retrieval or unconstrained debate.
in solving your problems with Enhans!
We'll contact you shortly!