

Author: Wonduk Seo, Juhyeon Lee, Yanjun Shao, Qingshan Zhou, Seunghyun Lee, Yi Bu
Enhans, Peking University, Yale University
Accepted by ACL 2026 Main
Paper Link: https://arxiv.org/html/2503.23314v2
TL;DR
- SPIO proposes an LLM-based automated data science framework that replaces rigid single-path workflows with sequential multi-path planning across four modules: data preprocessing, feature engineering, model selection, and hyperparameter tuning.
- The key idea is to let specialized agents generate multiple candidate strategies at each stage, then use an optimization agent to either select one best end-to-end pipeline or ensemble the top pipelines, rather than committing early to a single fixed path.
- SPIO has two variants: SPIO-S, which selects the single best pipeline, and SPIO-E, which ensembles top-ranked pipelines for stronger robustness. The framework conditions later decisions on intermediate evidence, making the pipeline more adaptive and more traceable than prior multi-agent systems.
- Across 12 benchmark datasets from Kaggle and OpenML, SPIO consistently outperforms strong baselines such as Zero-shot, CoT, Agent K, AutoKaggle, OpenHands, Data Interpreter, and AIDE, with an average performance gain of 5.6 percent. Ablation studies further show that top-ranked plans are indeed better, top-2 ensembling works best overall, and feature engineering plus hyperparameter tuning contribute most to the gains.
Abstract
This paper argues that recent LLM-based data science agents still suffer from rigid workflows and limited strategic exploration, which often leads to suboptimal pipelines. To address this, SPIO introduces a sequential planning framework in which multiple candidate strategies are generated and refined across four core stages of the machine learning pipeline. Instead of relying on one reasoning path, SPIO explicitly explores alternatives and then either selects or ensembles the best ones. The result is a more flexible, accurate, and reliable automated data science framework.
Introduction
The paper starts from the observation that building effective predictive pipelines still requires substantial manual effort, especially in preprocessing, feature design, model choice, and tuning. Although LLMs and recent multi-agent systems have improved automation, many of them still follow predefined stage structures or single-path reasoning. SPIO is proposed as a response to this limitation: rather than fixing one workflow in advance, it keeps multiple candidate paths alive and uses sequential evidence from earlier stages to improve decisions in later ones. This makes the overall process both more adaptive and easier to inspect.
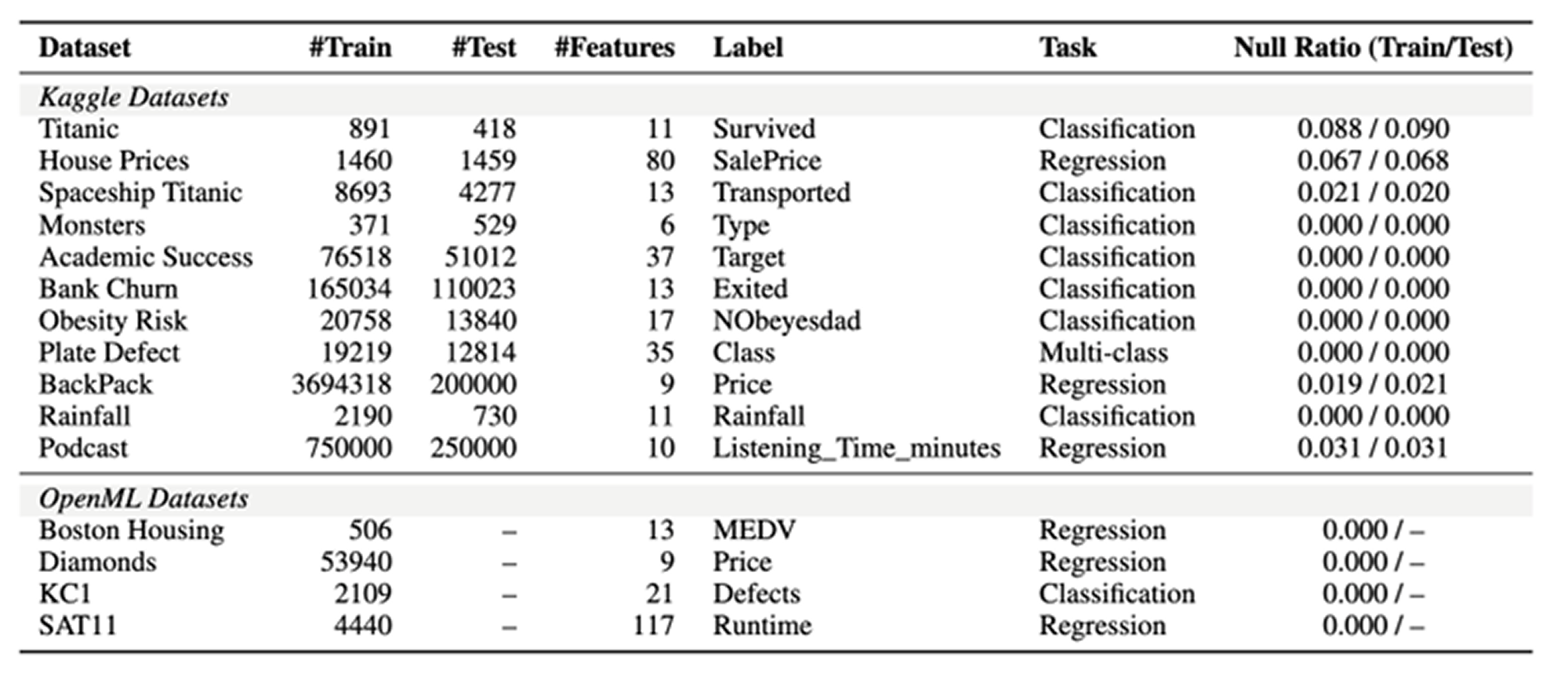
Datasets and Evaluation Setting
The experiments use two benchmark sources, Kaggle and OpenML, covering both classification and regression tasks across 12 datasets in total.
- Datasets: 8 Kaggle datasets, 4 OpenML datasets
- Generation backbones: GPT-4o, Claude 3.5 Haiku, LLaMA3-8B
- Main baselines: Zero-shot inference, Chain-of-Thought prompting, Agent K v1.0, AutoKaggle, OpenHands, Data Interpreter, AIDE
- Metrics: Accuracy for classification, RMSE for regression, ROC reported where applicable
Framework: SPIO
SPIO organizes automated data science into four modules: preprocessing, feature engineering, model selection, and hyperparameter tuning. Each module first uses a code generation agent to produce a baseline solution. Then a sequential planning agent proposes alternative strategies using the current code, its outputs, and prior planning history. This creates a structured search space of candidate plans across the full pipeline.
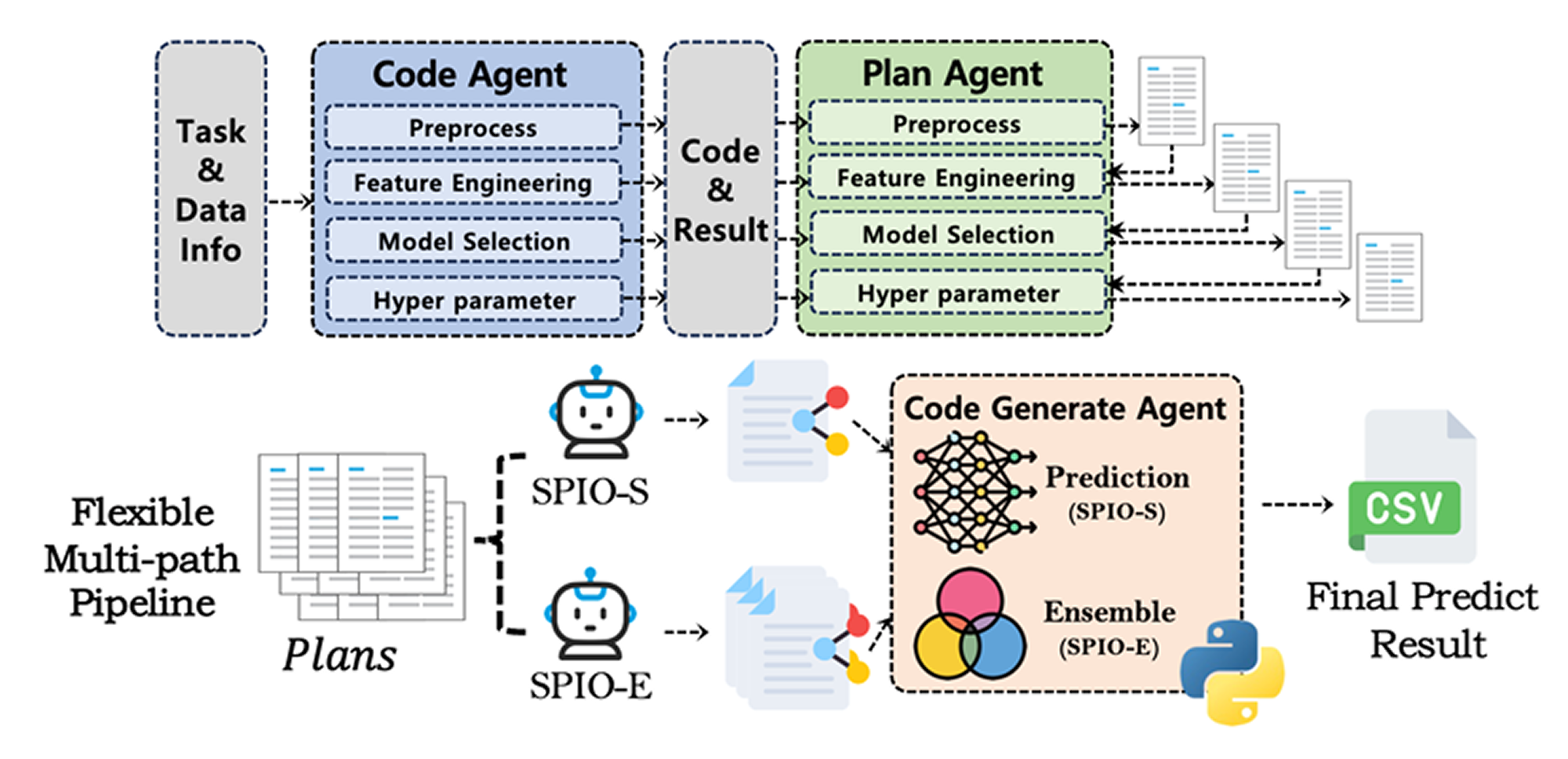
SPIO-S is the single-path version. It lets an LLM-driven optimization agent choose the best full pipeline from the candidate plan set, then generates final executable code from that selected plan.
SPIO-E is the ensemble version. It selects the top-k plans, generates code for each one, and combines their predictions through soft voting for classification or averaging for regression. In the experiments, the framework generates up to two candidate plans per module, and SPIO-E typically ensembles the top two full pipelines.
What makes SPIO different from prior systems is not just that it uses multiple agents, but that it explicitly reasons over multiple candidate strategies at each stage and connects later choices to earlier intermediate evidence. This means the framework does not merely refine code after execution, but performs plan-level reasoning over the whole pipeline.
Baselines
The main comparison set includes two simple prompting baselines and five recent multi-agent or autonomous agent systems. These are Zero-shot, CoT, Agent K v1.0, AutoKaggle, OpenHands, Data Interpreter, and AIDE. The paper positions SPIO against these methods by arguing that many of them either depend too heavily on a single reasoning path, follow rigid stage templates, or rely mostly on execution-driven improvement without explicit multi-path plan reasoning.
Experimental Results
The main result is that SPIO outperforms all strong baselines on average across the 12 benchmark datasets, with an average improvement of 5.6 percent. SPIO-S already shows strong gains through better plan selection, and SPIO-E often improves further by exploiting complementary strengths across top-ranked pipelines. The paper emphasizes that these improvements come from systematic exploration and staged optimization, not just from running more agent steps.
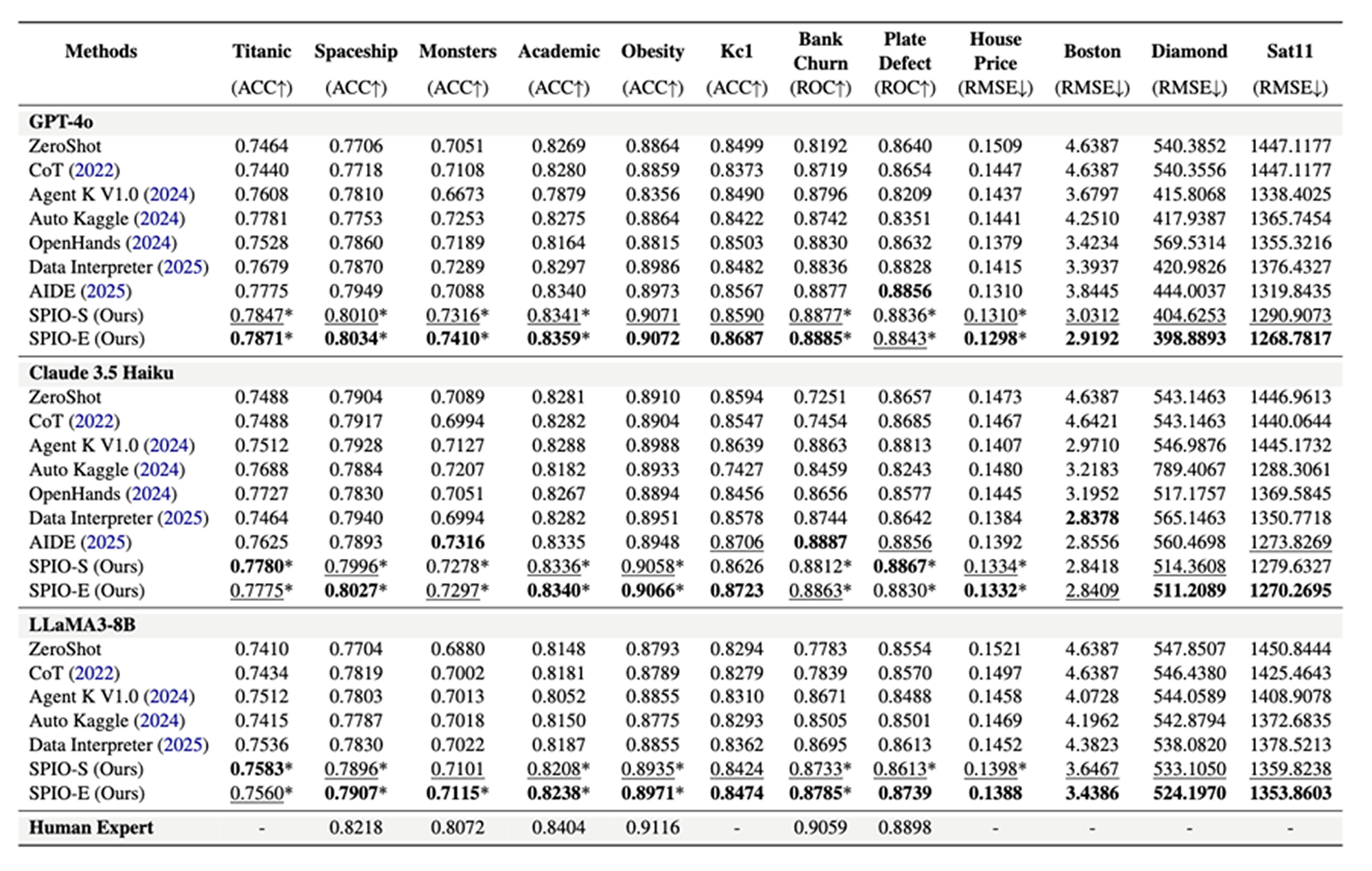
A notable qualitative takeaway is that SPIO conditions later-stage decisions on intermediate outputs such as transformed data summaries and validation scores. This lets it avoid brittle local decisions and makes its final choices more explainable at the module level. The paper also argues that this stage-wise trace gives stronger plan-level interpretability than methods that mainly rely on execution feedback loops.
Ablation Studies
The ablation analysis has three main findings. First, the LLM’s ranking is meaningful: the top-ranked candidate plan consistently performs better than lower-ranked alternatives. Second, ensembling two plans gives the best overall balance; adding more than two tends to introduce redundancy rather than further gains. Third, feature engineering and hyperparameter tuning appear to be the most important contributors, since removing them causes the largest performance drops.
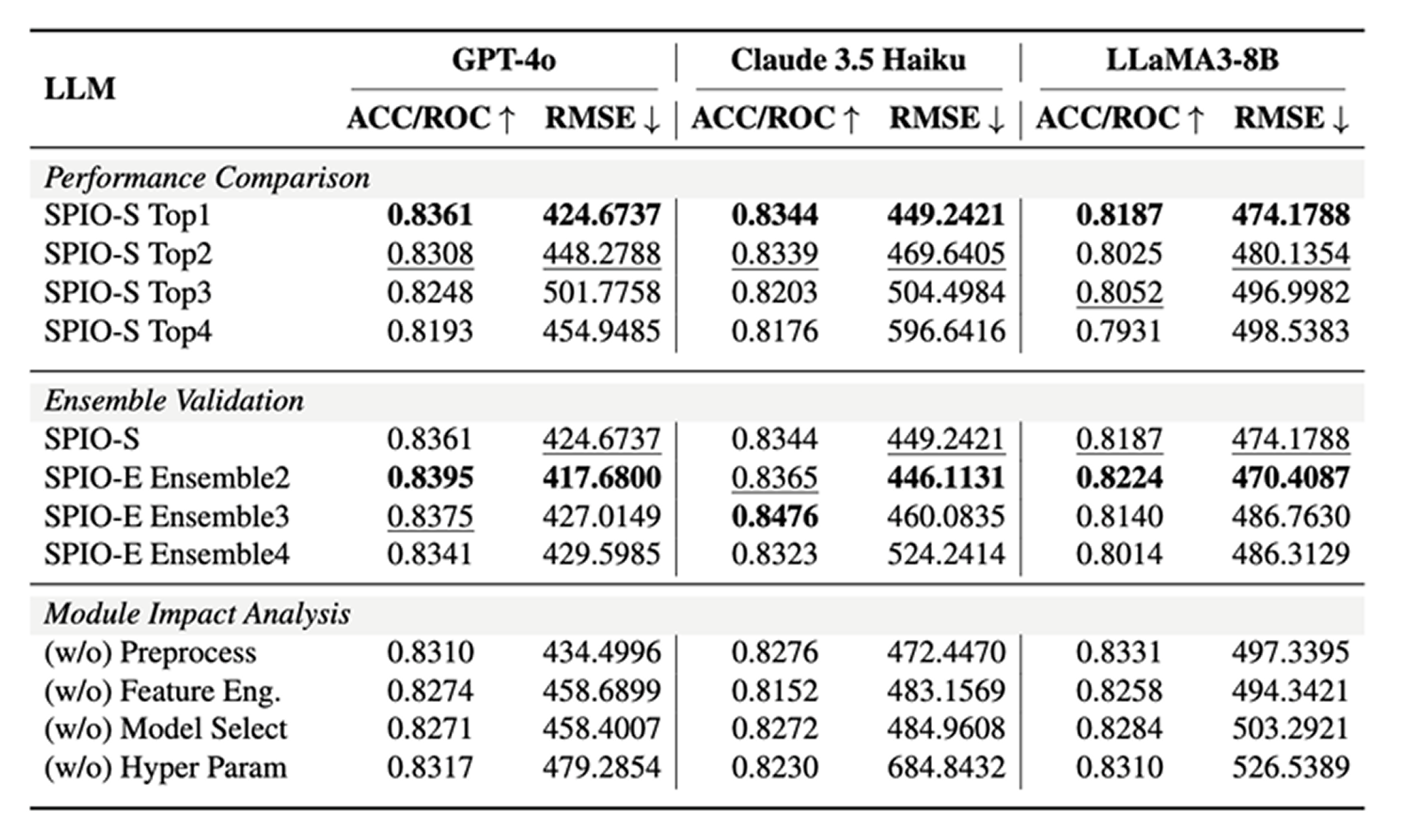
The paper also includes additional experiments on three Kaggle datasets released in 2025, which were unavailable during model pretraining. SPIO still outperforms the compared baselines there, suggesting that the gains are not simply due to memorization of older benchmark datasets.
Qualitative Study
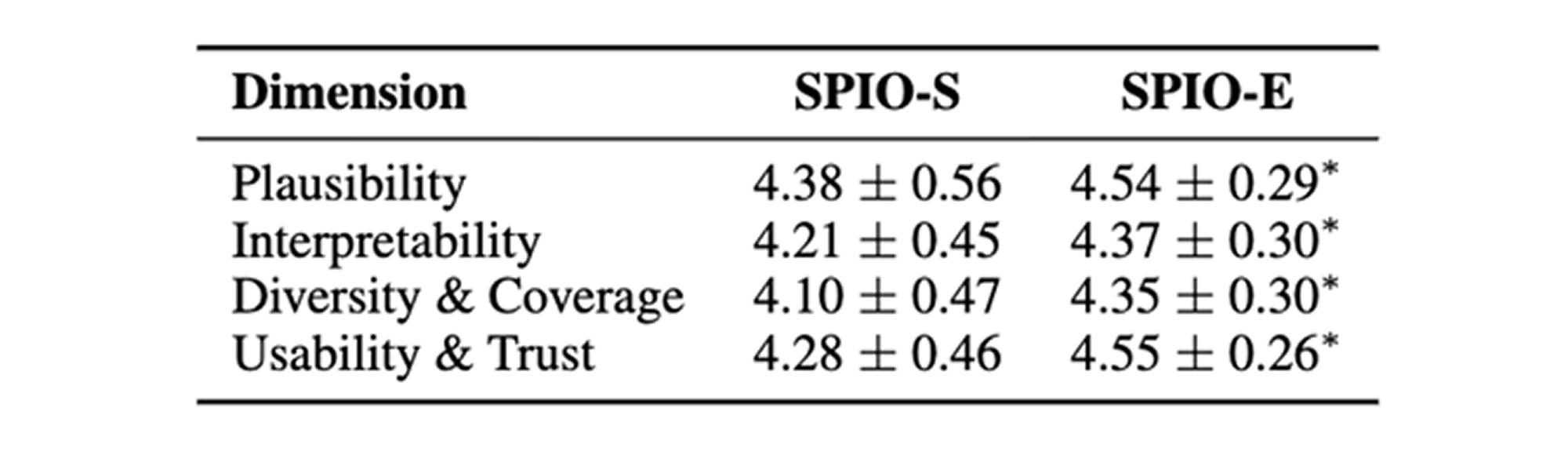
Beyond benchmark scores, the authors conduct an expert evaluation with 10 AI practitioners or graduate-level participants across 10 dataset-model pairs, yielding 100 evaluation instances. SPIO-E receives higher ratings than SPIO-S on plausibility, interpretability, diversity and coverage, and usability and trust. In a discrete plan-choice task, experts selected the top-ranked SPIO-E plan 72 percent of the time, which supports the claim that the framework’s internal ranking is aligned with human judgment.
Conclusion
The main contribution of SPIO is a structured multi-path reasoning framework for automated data science:
- sequential planning across four pipeline modules,
- explicit generation and comparison of multiple candidate strategies,
- single-path selection or top-k ensembling for final prediction,
- and evidence-aware optimization that links early pipeline outputs to later decisions.
Empirically, this design improves predictive performance, robustness, and interpretability over recent LLM-based baselines. The paper’s overall message is that automated data science benefits not only from more agentic behavior, but from better structured exploration over alternative pipeline plans.
in solving your problems with Enhans!
We'll contact you shortly!