

What Is Harness Engineering
LLM performance is no longer the bottleneck. Claude, GPT, Gemini all produce solid results. Yet the same problems keep showing up in enterprise environments.
- Agents that worked fine in demos break in production.
- Output consistency degrades as tasks get longer.
- Unverified results get shipped as-is.
No matter how capable the model, it cannot do reliable work without a structure that keeps it on track.
A horse's power only becomes useful when you put a harness on it. AI agents are no different. They need a control structure that directs that power. That is where Harness Engineering comes from.
From Prompts to Harness: How the Scope of AI Engineering Has Expanded
When AI tools first entered the picture, Prompt Engineering was the focus. The idea was simple: the quality of your output depends on how well you phrase your request.
→ Is it Important to Write a ‘Good’ Prompt?
→ Reducing Misinformation in Prompting
For simple tasks like drafting an email or summarizing a document, that was enough. But as enterprises started running longer, more complex workflows, the limits showed up fast.
- A single request cannot reliably carry a multi-step task to completion.
- AI tends to grade its own work generously.
- Quality breaks down when multiple stages are bundled into one prompt.
That gap gave rise to Context Engineering: the practice of structuring what information the model has access to at the moment it works, including memory, tool definitions, task history, and external data.
Both prompt engineering and context engineering operate inside the product. They optimize what goes into the model to get better output.
Harness Engineering works at a different layer. It is not about tuning what the model receives. It is about designing the entire development environment in which agents write code, verify it, and improve it. It structures how AI-built products get built in the first place.
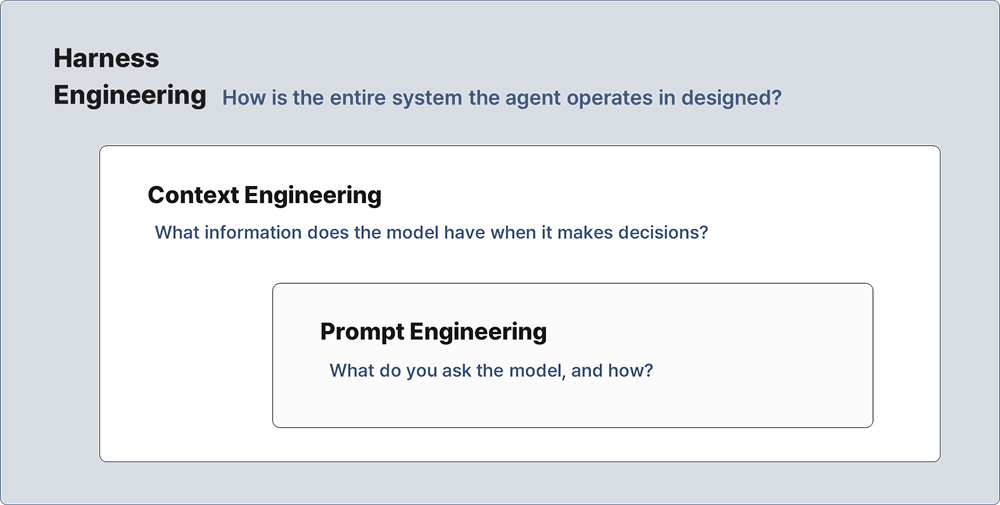
- Prompt Engineering: What do you ask the model, and how?
- Context Engineering: What information does the model have when it makes decisions?
- Harness Engineering: How is the entire system the agent operates in designed?
3 Engineers. 1 Million Lines of Code. None manually coded.
In February 2026, OpenAI published a case study that put Harness Engineering in concrete terms.
A team of three engineers completed roughly one million lines of code in five months. Not one line was written by a person. Codex agents wrote the code. Codex agents reviewed it. The engineers' job was not to write code. It was to design the environment and structure the agents worked inside. The team averaged 3.5 merged PRs per engineer per day, and productivity held as the team grew.
This is what AI-era engineering looks like in practice.
Agents Only Work With What They Can See
One of the structural elements in the OpenAI project was the AGENTS.md file, a machine-readable document sitting inside the GitHub repository that defines how agents are expected to work: which commands to run, which conventions to follow, which patterns to use.
From an agent's perspective, if something is not accessible in context, it does not exist. Discussions in a Slack thread, decisions logged in a Google Doc, knowledge sitting in someone's head: none of that reaches the agent.
That is why everything the agent needs has to live in the repository in a form it can read: documentation, architecture rules, quality standards, execution plans.
The Core Components of a Harness
Harness design varies by domain and team. But certain layers show up consistently in practice, and in open-source implementations like revfactory/harness, the same patterns repeat: task decomposition, role separation, and verification structure.
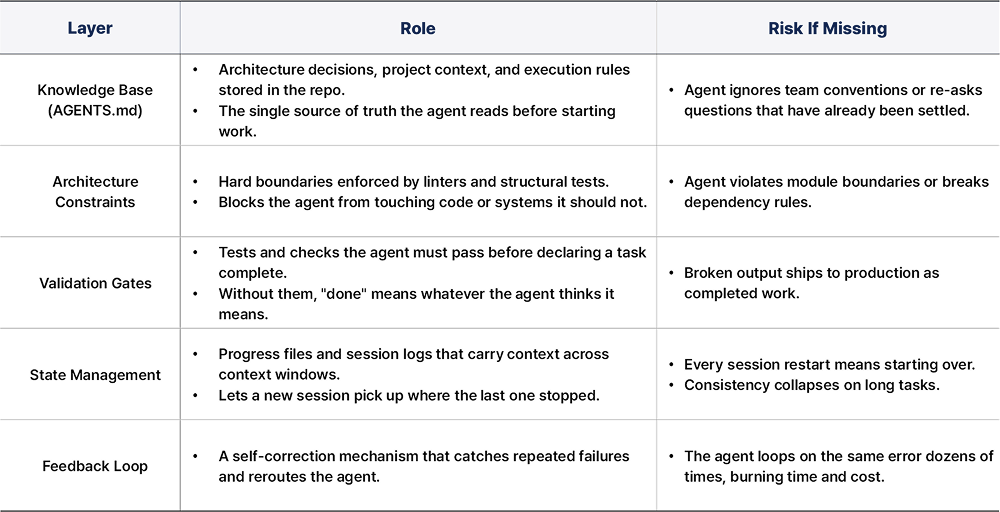
None of these are prompts. None of them are context. They are structural, and the agent operates within them whether it wants to or not.
More Constraints, More Stable Output
Based on Aakash Gupta's analysis, applying a harness increases upfront cost but significantly improves output quality and long-term maintainability.

The Engineer's Role Is Shifting Toward Structure Design
On a team that has adopted Harness Engineering, the workday looks different. Instead of writing code, engineers update AGENTS.md, add tests to validation gates, and analyze failure patterns from the night before to encode them as lint rules.
Team structure shifts too. In a harness-based multi-agent setup, roles separate out: someone owns harness design and architecture constraints, someone manages the knowledge base and context quality, someone defines validation criteria and feedback loops. AI system operation moves from an individual skill to a team-level engineering problem. Code review gives way to harness design review.
The skill that matters is no longer writing code fast. It is building an environment that agents can work in reliably. That is what separates teams in enterprise AI now.
How Enhans Applies Harness Engineering
Here is a concrete example from an Enhans engineer's daily workflow.
He manages multiple repositories at once. This project needs tests run first. That one requires documentation updates before any API changes. Another follows a specific branch strategy. All of that knowledge lives in his head. Restating it to an agent every time a task starts does not scale.
His solution is a workspace orchestrator. One developer splits into multiple agents: one writes code, one reviews it, one tracks bugs, one documents design decisions. The developer does not manually direct each one. Instead, rules accumulated per repository are defined in files, and agents operate within those rules.
Three-Layer Structure
The workspace orchestrator system runs on three layers.
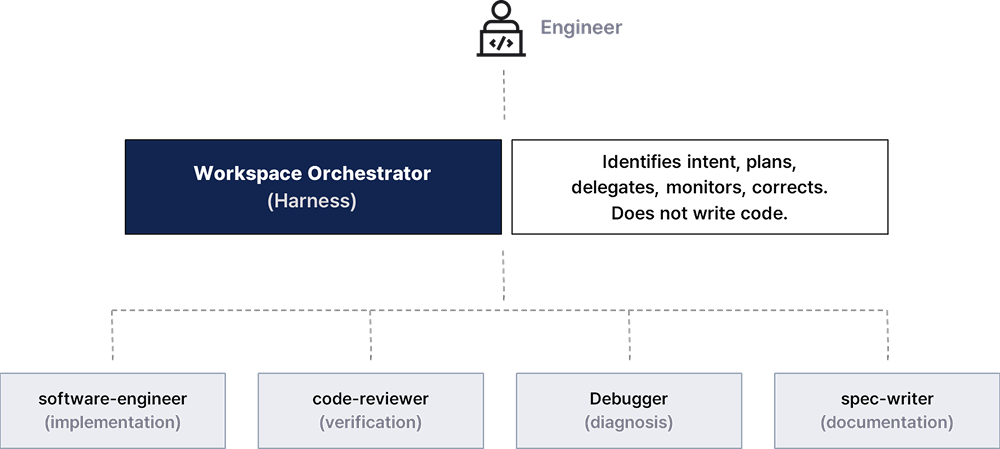
The developer sets direction and approves. The orchestrator layer acts as the harness: it takes the request, identifies intent, builds a plan, delegates to agents, monitors results, and corrects when something goes wrong. It does not write code. The actual work goes to four agents, each with a role definition file that specifies clearly what they do and what they do not do.
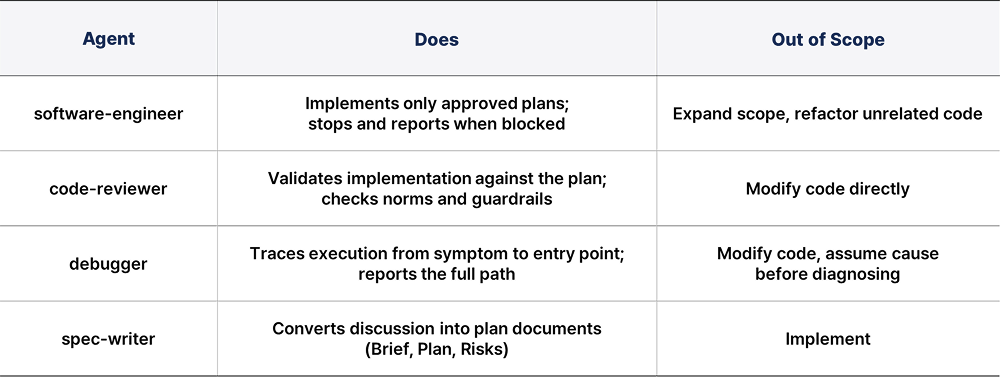
The Rule System
Two types of rule files govern agent behavior.
- Norms are the principles agents use to make judgments. For example: "If you can verify something from the code, do not ask. Decide." "Do not defer to the user's opinion. If there is a logical problem, push back with reasoning." "After implementation, re-read the norms and run a self-check before deployment.”
- Guardrails are the hard boundaries agents cannot cross. For example: "Do not draw conclusions about context outside the code from the code alone." "When asked to reconsider, do not carry forward your previous conclusion. Start the check from scratch."
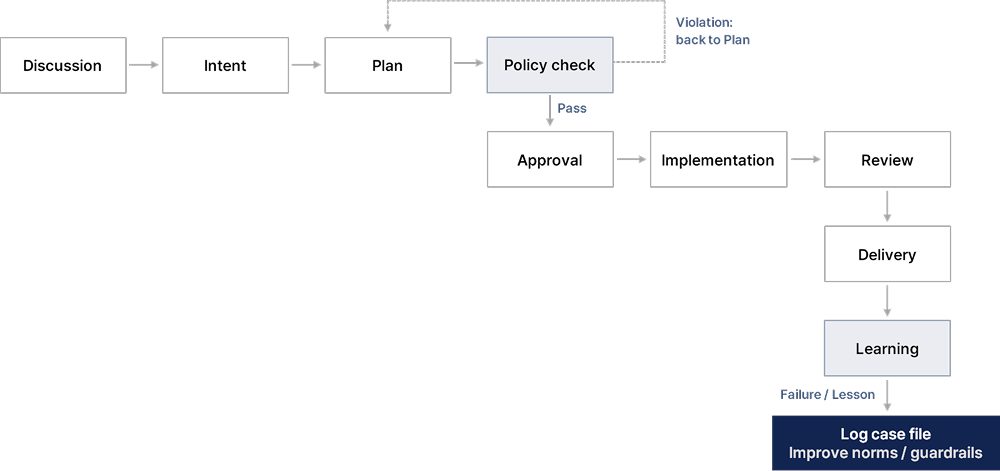
The core rule of the entire workflow: no implementation begins without an approved plan. All progress is logged to a per-project thread document.
Feedback Loop: Failures Become Rules

The most notable part of this system is the automatic learning circuit. When the developer sends a correction signal ("don't do that," "not that one," "why does this keep happening"), hooks detect it and write it to a buffer file. When context compression happens, that signal gets reinjected into the agent's context.
The agent reads the signal, decides whether a behavior adjustment is needed, and if so, logs a case file or proposes an update to the norms and guardrails. Even when context resets, the correction signal survives. Repeated failures turn into structural improvements.
The entire system contains no application code. A few markdown files, one JSON config, two shell scripts. It shows that agent behavior can be structured and agents can learn from failure using nothing but native agent capabilities.
Conclusion
1. Structure is what makes AI work at scale.
No matter how capable the model, it will not hold up in an enterprise environment without a structure that keeps it on course. When agents that worked in demos fall apart in production, the missing piece is almost always design structure, not model performance.
2. The scope of engineering is expanding.
Prompt engineering handled single tasks. Context engineering extended that to multi-step work. Harness engineering covers complex, enterprise-scale automation as a whole. These are not alternatives. Each builds on the previous one.
3. Starting now beats starting later.
The performance gap between Claude, GPT, and Gemini is closing. The edge going forward will not come from which model you use. It will come from how well you design the structure that model works inside. A harness, once properly built, remains effective even as models change. Teams that build it now will be six months ahead of teams that start later.
in solving your problems with Enhans!
We'll contact you shortly!