

Andrej Karpathy, co-founder of OpenAI and former Tesla AI Director, shared that as of December 2025, the share of code he writes directly dropped from 80% to nearly zero. As agents took over coding, researchers found themselves spending their time elsewhere.
That raised a harder question: can agents also handle failure analysis, reading papers, and finding paths forward? Auto Research started there. If an agent can autonomously and repeatedly design experiments, analyze failures, search literature, and revise code, researchers can remove themselves from the bottleneck entirely.
Enhans built this with its own architecture: an Auto Research AI system that connects failure analysis and academic literature search into a single loop.
What Existing AutoML Cannot Solve
Existing AutoML approaches like Neural Architecture Search and Hyperparameter Optimization only search within predefined parameter ranges. Humans design the search space first, and anything outside that range stays unexplored.
Changing the structural logic of code (agent behavior strategies, environment interaction logic, error recovery mechanisms) falls outside the scope of parameter search. Existing AutoML adjusts parameter values. It cannot analyze why an agent failed or change the strategy itself.
The same limitation applies to literature. Existing AutoML systems have no mechanism to automatically gather recent research and incorporate it into improvement strategies. Reading papers and extracting ideas remains entirely manual work.
Auto Research is Enhans' attempt to solve both problems.
Auto Research AI System Architecture
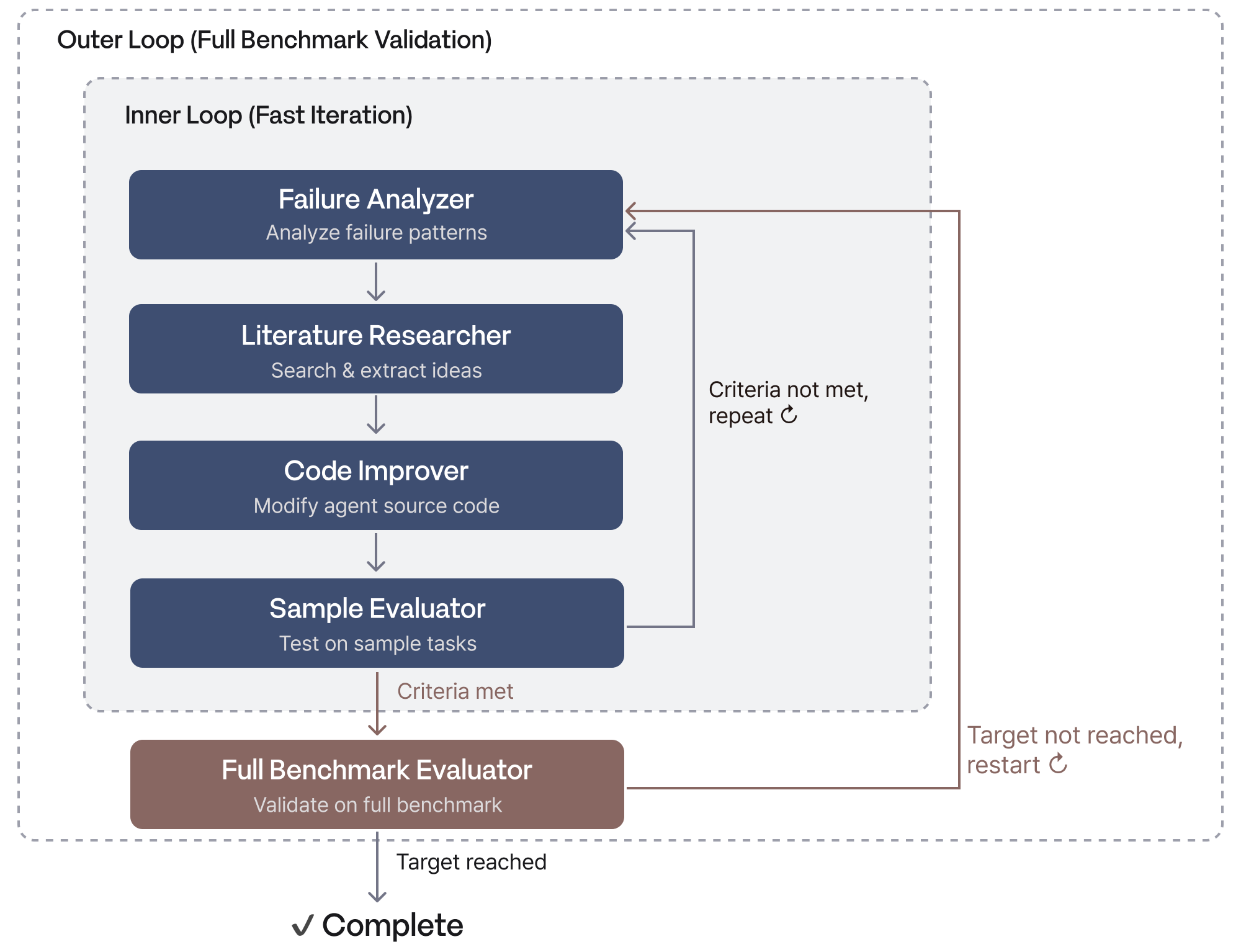
The system is organized into three layers. An orchestrator controls the overall execution flow, a dual-loop engine runs the research cycle, and specialized agents handle each stage.
- Orchestrator: Runs failure analysis, literature review, and code improvement each as an independent LLM session. Automatically detects whether this is a first run or a continuation of an agent-based improvement loop, and executes the appropriate workflow.
- Dual-loop structure: The inner loop iterates quickly on a subset of failed tasks to improve the agent. The outer loop validates generalization performance against the full benchmark. Fast experimentation and stable validation are separated, allowing convergence to target performance without overfitting.

Failure Analysis, Literature Search, and Code Improvement in One Loop
The inner loop of Auto Research connects the following modules in sequence. Each module's output becomes the next module's input, and the cycle runs autonomously.
- Failure Analyzer: Automatically analyzes tasks where the agent failed, identifying failure patterns and root causes. Classifies failures by pattern and stores them as structured documents. This analysis document feeds the next stage.
- Literature Researcher: Takes the failure analysis as input, then automatically retrieves and analyzes relevant academic papers. Searches only recent research, with the LLM reading each paper and extracting ideas that could address the current failure patterns. Each idea is logged with its source paper, key insight, and proposed application. Ideas drawn from papers connect directly to code improvement.
- Code Improver: Takes the failure analysis document and paper ideas as input and automatically revises the agent's source code. The LLM synthesizes the failure patterns and paper ideas into a code revision plan, then improves decision logic, environment interaction, and error recovery mechanisms.
- Sample Evaluator: Runs the revised agent on a subset of sample tasks rather than the full benchmark to quickly verify whether performance has improved. This serves as a pre-validation step before the full benchmark run. Only when improvement is confirmed does the system proceed to the outer loop's full benchmark evaluation.
Agent Harness: One LLM, Multiple Specialist Roles
One of the key differentiators of this system is agent harnessing. A general-purpose LLM is assigned a specific role and set of constraints at each stage, shaping its behavior for that purpose.
The same LLM performs distinct specialist roles across each stage: failure analyst, academic researcher, software engineer, test runner, and evaluation analyst. No separate specialized model training is required. Because each session runs independently, a mistake in one role does not propagate to others.
Global rules maintain consistency across the entire system, while specific goals and constraints are passed individually at each stage. As the loop progresses, the agent's improvement strategy adjusts autonomously to fit the current state.
Research Context Persists Across Sessions
Each research stage runs as an independent LLM session. Independent sessions create a risk of losing context from previous stages. Enhans' Auto Research system solves this through text-based context log files as the shared medium.
Each session operates in three consistent steps. It starts by reading the context log file to understand the accumulated context from prior sessions. It then performs the work corresponding to its role. Upon completion, it compresses what it did into a single paragraph and appends it to the log file. The Nth session acquires the accumulated context from sessions 1 through N-1 this way.
This structure lets the system maintain long-term research context while working around LLM context window limits. Passing information in compressed summary form also prevents unnecessary token consumption.
All communication between the orchestrator and agents passes through the file system. Every input and output is preserved as a file, making debugging and reproduction possible. If a failure occurs at any stage, the input file for that stage remains available for re-execution.

When Auto Research AI Works Best
The loop requires an objective metric that can automatically determine success or failure. Tasks with quantitative outcomes (web agent benchmarks, code generation evaluation, autonomous driving simulation) fit this requirement.
The framework is designed to be domain-agnostic. The target agent, benchmark, evaluation method, and literature search strategy are all replaceable modules, making the same structure applicable across web agents, autonomous driving, robot control, scientific discovery, and more.
There are limits in areas that require subjective judgment. When the validation criteria themselves are unclear, the loop does not converge. Starting in domains with objective metrics and expanding incrementally is the practical approach.
The Age of Agents Changing Research
Karpathy shared the next goal for Auto Research on his personal social media: "The goal is not to mimic a single PhD researcher, but to mimic an entire research community of many researchers."
Just as coding shifted to agents, repetitive experiment design and literature search will follow. As failure analysis and paper search become automated, researchers can focus entirely on deciding where to look next. One researcher can manage dozens of experiments in parallel.
That shift has already started. While agents fill the search space, researchers can direct their attention to higher-order questions.
in solving your problems with Enhans!
We'll contact you shortly!