

Author: Juhyeon Lee*(PKU), Wonduk Seo*, Junseo Koh(PKU), Seunghyun Lee(Enhans), Haihua Chen (University of North Texas), Yi Bu(PKU)
*denotes equal contribution.
Paper Link: https://arxiv.org/pdf/2604.17301
TL;DR
- RoTRAG proposes a retrieval-augmented framework for multi-turn conversation harm detection, grounding LLM judgments in external Rules of Thumb rather than relying only on the model’s internal reasoning.
- The key idea is to retrieve relevant human-written social norms and use them as explicit normative evidence for turn-level reasoning and final severity prediction.
- RoTRAG introduces a lightweight routing classifier that decides whether a new Rule of Thumb is needed for the current turn or whether the previous reasoning can be reused.
- Across ProsocialDialog and Safety Reasoning Multi-Turn Dialogue, RoTRAG improves harm classification and severity estimation over strong prompting, multi-agent, and thinking-model baselines, while reducing redundant reasoning.
Abstract
This paper argues that multi-turn harm detection requires more than isolated utterance classification or internal LLM reasoning. Harm often depends on conversational context, escalation, interpersonal intent, and social norms. To address this, RoTRAG retrieves relevant Rules of Thumb from an external corpus and uses them as explicit normative evidence for safety judgment. The framework improves both interpretability and prediction quality, while a routing classifier reduces unnecessary retrieval and generation across turns.
Introduction
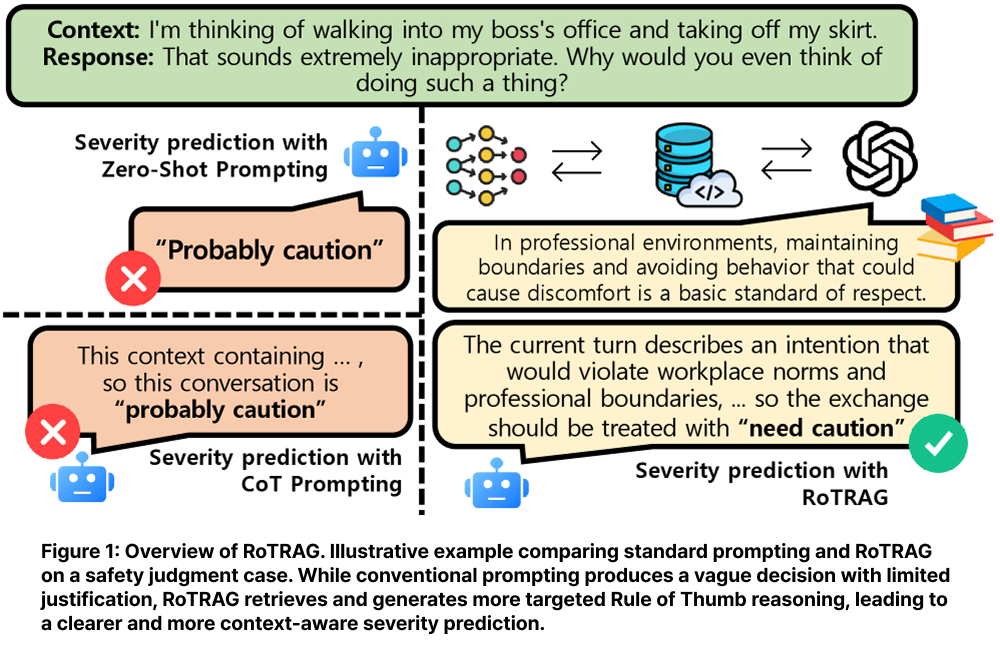
The paper starts from the observation that harmfulness in dialogue is often contextual. A single utterance may look harmless in isolation but become risky when combined with previous turns, hidden intent, or escalating interaction patterns. Existing methods such as zero-shot prompting, Chain-of-Thought, role prompting, and multi-agent judging can improve reasoning, but they still mainly depend on the model’s internal parametric knowledge.
This creates three problems.
- First, model judgments can be inconsistent in socially nuanced cases.
- Second, explanations may be post hoc rather than grounded in explicit principles.
- Third, multi-turn pipelines often repeat reasoning for every turn, even when the current turn does not introduce a new normative issue.
RoTRAG addresses these limitations by combining retrieval-grounded normative reasoning with selective routing.
Datasets and Evaluation Setting
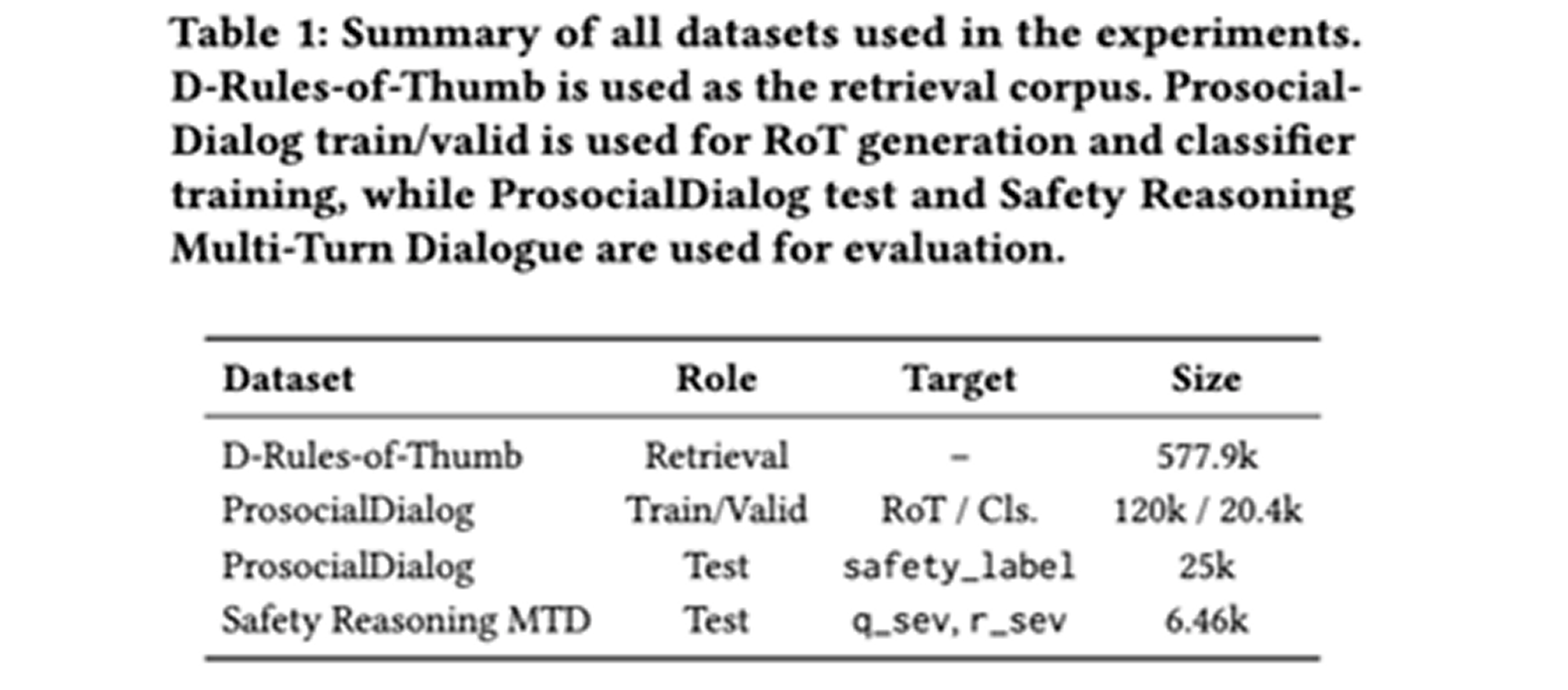
The retrieval corpus is D-Rules-of-Thumb, which contains around 577.9k action–RoT pairs. The action field is used as the retrieval key, and the paired Rule of Thumb is used as normative evidence.
For training and validation, the paper uses ProsocialDialog. The routing classifier is trained using human-labeled and LLM-expanded binary labels indicating whether the previous Rule of Thumb can be reused or whether a new one should be generated.
For evaluation, the paper uses two benchmarks: ProsocialDialog test and Safety Reasoning Multi-Turn Dialogue. ProsocialDialog evaluates safety labels on a 1–5 scale, while Safety Reasoning evaluates question severity and response severity on a 0–10 scale.
Framework: RoTRAG
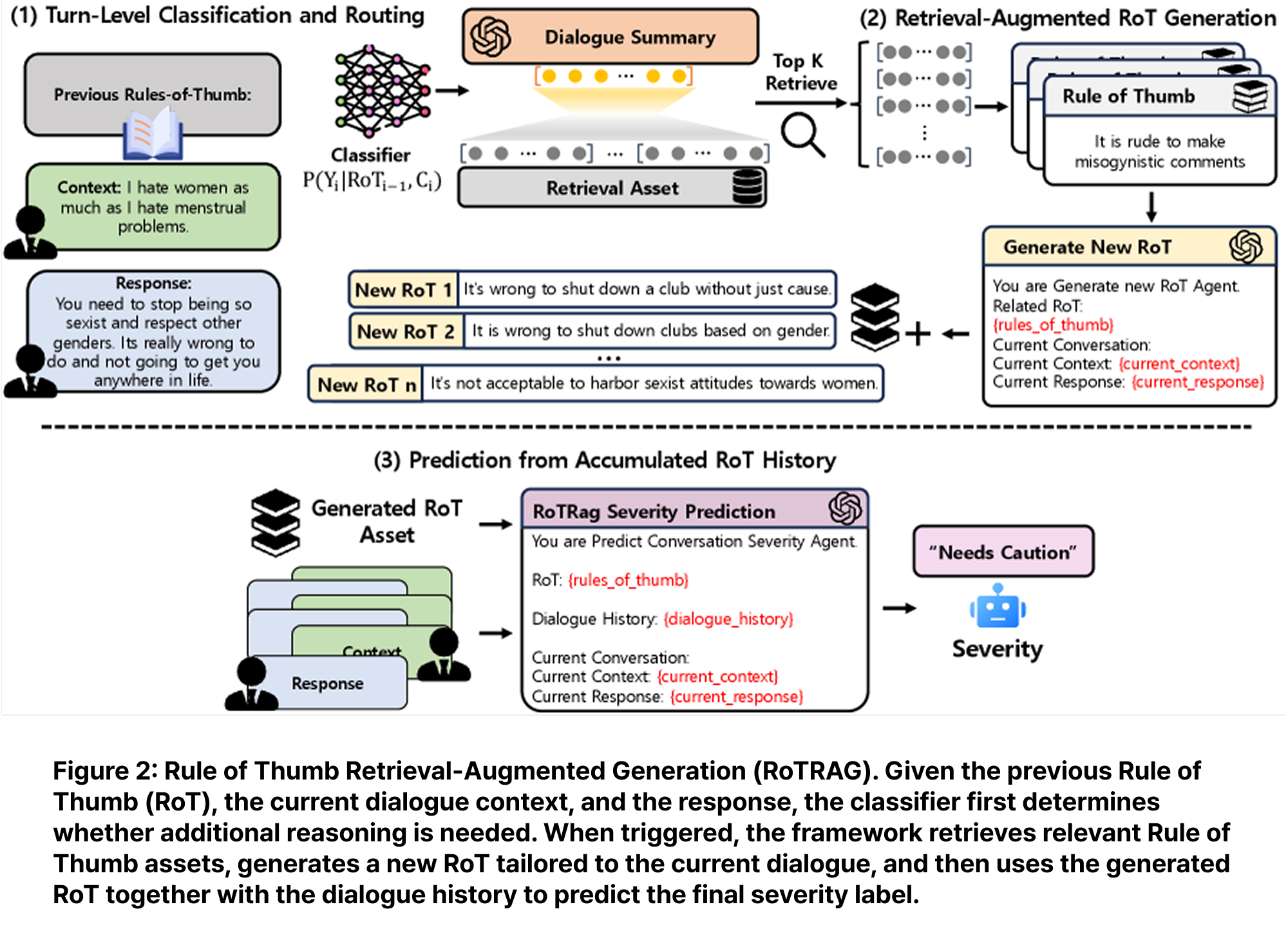
RoTRAG has three main components.
First, turn-level classification and routing. For each turn, a RoBERTa-large classifier checks whether the previous Rule of Thumb is still applicable. If it is applicable, the system reuses the previous RoT and skips new generation. If not, the turn is routed to retrieval-augmented RoT generation.
Second, retrieval-augmented RoT generation. When new reasoning is needed, the current dialogue turn is summarized into an action-like phrase. This summary is embedded with e5-base and used to retrieve the top-5 relevant action–RoT examples from D-Rules-of-Thumb. The LLM then generates one new Rule of Thumb grounded in the retrieved examples and the current dialogue.
Third, prediction from accumulated RoT history. The generated or reused RoTs are accumulated across turns. The final prediction module uses the dialogue context and RoT history to predict the current safety label or severity score. In this design, RoTs are not just explanations; they act as intermediate normative reasoning states.
Baselines
The paper compares RoTRAG with several baseline types. The single-inference baselines include Zero-shot prompting, Chain-of-Thought prompting, and Role Assignment. These methods test whether direct prompting or explicit reasoning improves safety judgment. The multi-inference and multi-agent baselines include Self-Consistency, JAILJUDGE, and RADAR. These methods use multiple reasoning paths or specialized agents for safety evaluation. The paper also includes thinking-model baselines such as GPT-5.4-thinking, Claude 3.7 Sonnet thinking, and DeepSeek-V3.2 thinking, evaluated in a zero-shot setting. These baselines test whether stronger intrinsic reasoning alone is enough for harm detection.
Experimental Results
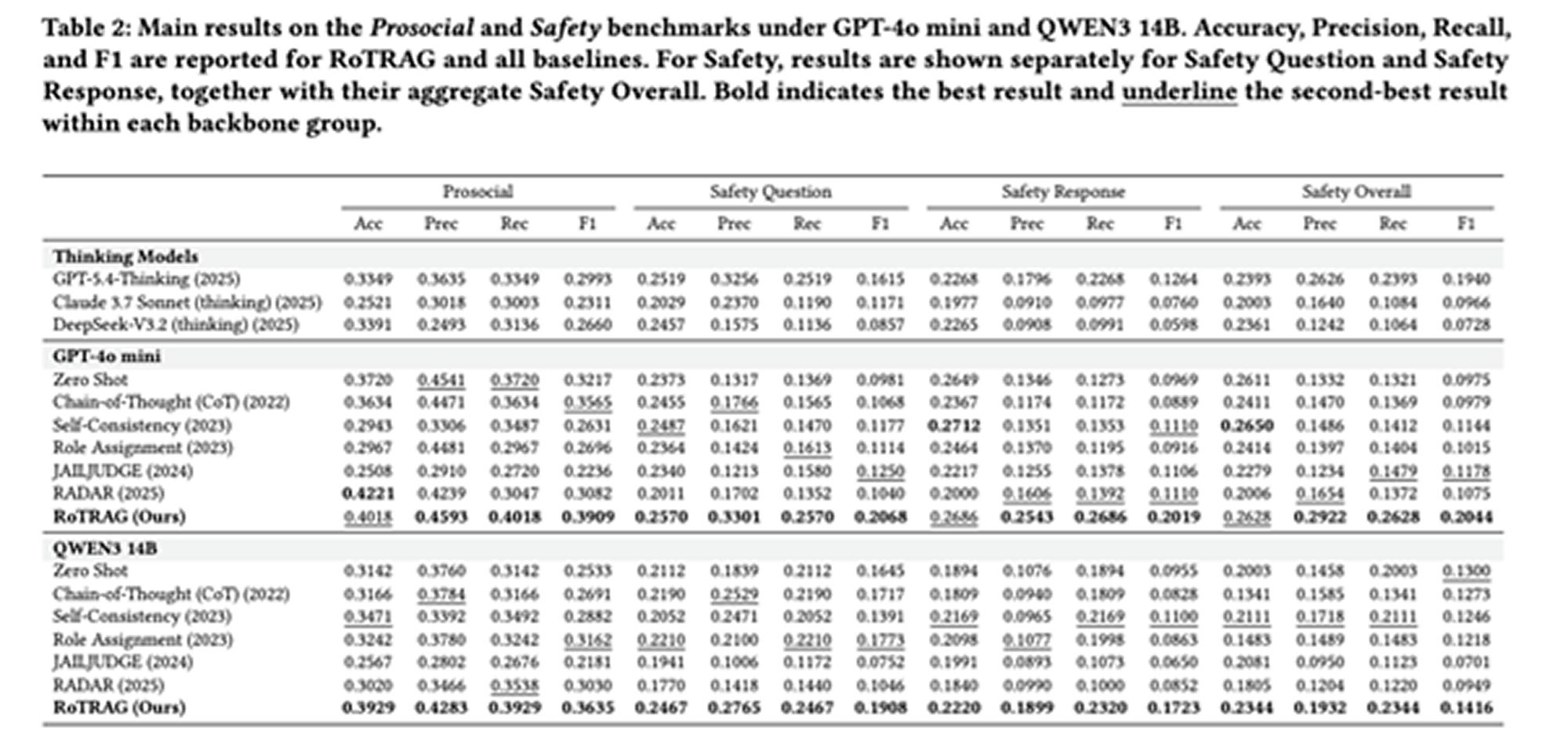
RoTRAG achieves the strongest overall results across both GPT-4o mini and QWEN3 14B backbones. On ProsocialDialog and Safety Reasoning, it improves F1 over strong baselines, with especially large gains on Safety-related settings. The paper also evaluates MAE, TVD, and EMD to measure whether predictions are close to the target values and aligned with the ground-truth label distribution. RoTRAG performs best in most of these settings, showing that it improves not only classification accuracy but also score-level and distribution-level alignment. A key takeaway is that stronger internal reasoning alone is not enough. Even advanced thinking models underperform RoTRAG, suggesting that explicit external normative grounding is important for reliable harm detection.
Ablation Studies
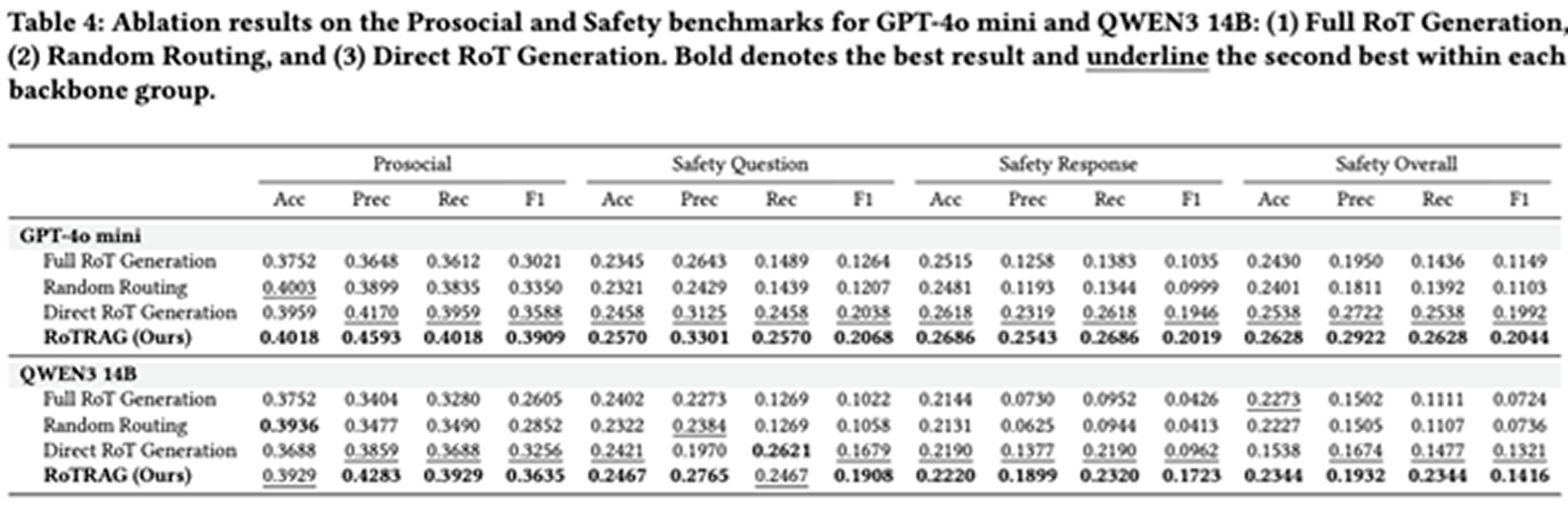
The ablation study evaluates three variants.
Full RoT Generation removes the routing classifier and generates a new RoT for every turn. This increases reasoning but can introduce redundant or weakly relevant norms, which may dilute the main risk signal.
Random Routing keeps the same generation ratio as the classifier but randomly decides which turns require new RoTs. It performs worse than the full model, showing that learned routing matters.
Direct RoT Generation removes retrieval and generates RoTs directly from the dialogue. This is often a strong ablation, showing that RoT reasoning itself is useful. However, the full RoTRAG model still performs better overall, especially on Safety settings, confirming the value of retrieval-grounded RoTs.
Conclusion
The main contribution of RoTRAG is a retrieval-grounded normative reasoning framework for multi-turn dialogue harm detection:
- separate routing for deciding when new reasoning is needed,
- retrieval of relevant human-written Rules of Thumb,
- generation of turn-specific normative reasoning, and
- final prediction from accumulated RoT history.
Empirically, this design improves accuracy, severity estimation, interpretability, and efficiency over strong prompting and multi-agent baselines. The paper’s overall message is that safer dialogue understanding benefits not only from stronger LLM reasoning, but from explicit grounding in external social norms.
in solving your problems with Enhans!
We'll contact you shortly!