

tl;dr
- ValuesRAG adds real-world value data (such as the World Values Survey) to your LLM so it responds in a more culturally aware and less biased way.
- Instead of relying on a fixed persona, it uses retrieval (RAG) to bring in the right local context for each question, which improves accuracy and reduces misunderstandings.
- This approach is practical for Commerce AI and AI Agents, helping customer service sound local, brand protection policies read clearly, and marketing copy align with regional norms.
- It also works with Agentic AI and LAM (Large Action Model) pipelines so the system can trigger the correct follow-up actions after generating a response.
- The result is higher user trust, better conversion, and AI that matches how people actually think and speak in each region.
Author:Wonduk Seo (서원덕)1,Zonghao Yuan2, Yi Bu3
1.Enhans 2. Tsinghua University 3. Peking University
Accepted by AAAI/ACM Conference on AI, Ethics, and Society (AIES)
Abstract
Ensuring cultural values alignment in Large Language Models (LLMs) remains a critical challenge, as these models often embed Western-centric biases from their training data, leading to misrepresentations and fairness concerns in cross-cultural applications. Existing approaches such as role assignment andfew-shot learning struggle to address these limitations effectively due to their reliance on pre-trained knowledge, limited scalability, and inability to capture nuanced cultural values. To address these issues, we propose ValuesRAG,a novel and effective framework that applies Retrieval-Augmented Generation(RAG) with In-Context Learning (ICL) to integrate cultural and demographic knowledge dynamically during text generation. Leveraging the World Values Survey(WVS) dataset, ValuesRAG first generates summaries of values for eachindividual. We subsequently curate several representative regional datasets toserve as test datasets and retrieve relevant summaries of values based on demographic features, followed by a reranking step to select top-k relevant summaries. We evaluate ValuesRAG using 6 diverse regional datasets and show that it consistently outperforms baselines, both in main experiments and ablation settings. Notably, ValuesRAG achieves the best overall performance over prior methods, demonstrating its effectiveness in fostering culturally aligned and inclusive AI systems. We further conduct two qualitative casestudies to illustrate how ValuesRAG retrieves demographically aligned value profiles, enabling more context-sensitive reasoning without relying on static prompts or stereotypes. Our findings underscore the potential of retrieval-based methods to bridge the gap between global LLM capabilities and localized cultural values.
Introduction
LargeLanguage Models (LLMs) have become central to a wide range of applications,from conversational agents to decision-support systems. However, their training on predominantly Western-centric corpora has led to embedded cultural biases that limit their global applicability and risk producing outputs thatmisrepresent or marginalize non-Western perspectives. These biases present critical challenges for deploying LLMs in cross-cultural contexts, where fairness, inclusivity, and trust are essential. Although prior approaches suchas role-assignment and few-shot prompting have been proposed to mitigate theseissues, they often rely on static demographic roles or a narrow set of examples. As a result, they struggle to capture the nuanced and multifaceted nature of cultural values across diverse populations.
Addressing this challenge requires frameworks that move beyond static or example-based adjustments and can instead integrate structured cultural knowledge dynamically during text generation. One major obstacle has been the scarcity of large-scale, accessible cultural datasets and the difficulty of aligning such data with generative reasoning processes. At the same time, variability in cultural expression within regions and the risk of reinforcing stereotypes when relying solely on pretrained knowledge further complicate alignment efforts. To overcome these barriers, we propose ValuesRAG, a repurposed retrieval-augmented framework that leverages structured cultural datasets to provide contextually rich guidance for LLM outputs. By retrieving and reranking values-based summaries from the World Values Survey (WVS) and aligning them with demographic features, ValuesRAG aims to improve fairness, inclusivity, and contextual sensitivity in cross-cultural applications.
Materials and Methods
Datasets and Population
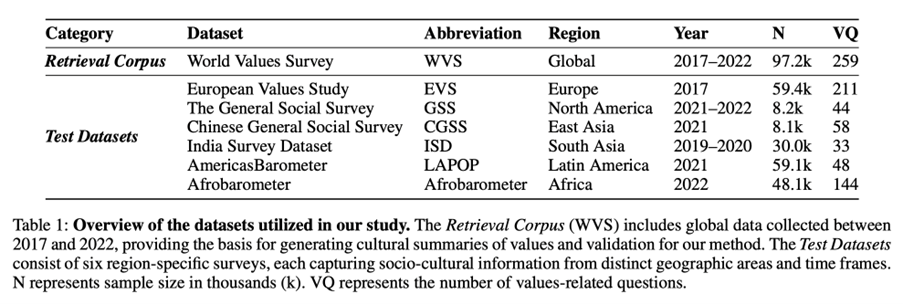
In this multi-dataset retrospective validation study, we evaluated the diagnostic performance of ValuesRAG across six regional test datasets: European Values Study (EVS), General Social Survey (GSS, North America), Chinese General Social Survey (CGSS), India Survey Dataset (ISD), Latin America Public Opinion Project(LAPOP), and Afrobarometer (Africa). These datasets collectively span over 200,000 individuals surveyed between 2017–2022, covering a wide range of demographic and cultural variables. The World Values Survey (WVS, Wave 7)served as the retrieval corpus, providing over 97,000 respondents’ values and demographic profiles across 120 countries. Inclusion criteria required datasets to contain both demographic information and values-related questions with direct or near-direct mapping to WVS categories. Exclusion criteria included datasets lacking sufficient overlap with WVS demographic features or those within complete/questionnaire corruption.
Reference Standard
The WVS was used as the reference standard,given its global representativeness, rigorous design, and frequent adoption in cross-cultural studies. Cultural values dimensions included: (1) social values and trust, (2) wellbeing, (3) political culture and regimes, (4) ethical and religious values, (5) perceptions of corruption, migration, and security.Regional datasets were matched against WVS items for consistency, and discrepancies were resolved by consensus mapping.

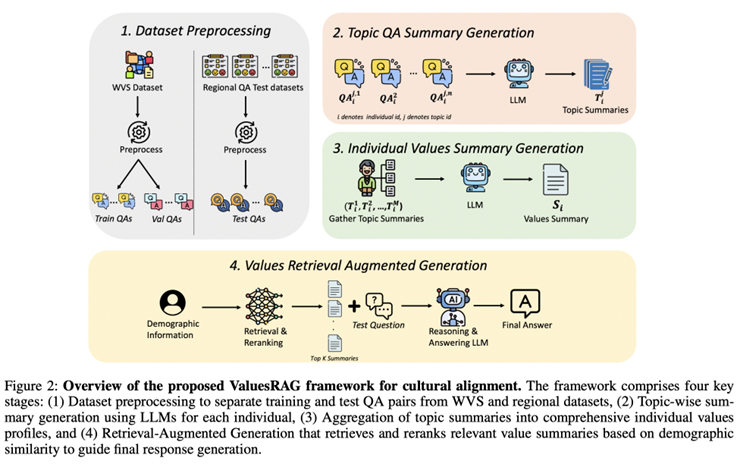
ValuesRAG Framework
The framework integrates three components:
1.Values and Demographic Summary Generation: individual-level summaries were generated from WVS by grouping topic-wise values with demographic metadata.
2.Retrieval and Reranking: for each test individual, the top-100 most demographically similar summaries were retrieved using an embedding model (E5-base) and refined using a multilingual reranker. The final top-k (optimized at k=3) were selected.
3.Values-Augmented Generation: retrieved summaries were concatenated with demographic information and test questions to guide the LLM in producing contextually aligned responses.
Statistical Analysis
Performance was assessed using accuracy as the primary endpoint, consistent with values-related QA evaluation standards. Accuracy was reported with 95%confidence intervals (CI). Sub-analyses stratified by region and by retrieval depth (k=1, 3, 5, 10) were performed to assess robustness. Optimal retrieval depth was determined by maximizing agreement between retrieved summaries and test responses. Baseline methods(zero-shot, role-assignment, few-shot, hybrid) were evaluated as comparators. Statistical significance was assessed using paired t-tests with Holm-Bonferroni correction (p<0.05 considered significant).
Results
Population
Across all six regional datasets, 212,000 individuals were included in the study,spanning diverse demographic categories (e.g., age, sex, education, religion,income). The distribution of cultural questions ranged from 33 (ISD) to 211(EVS).
Overall Performance
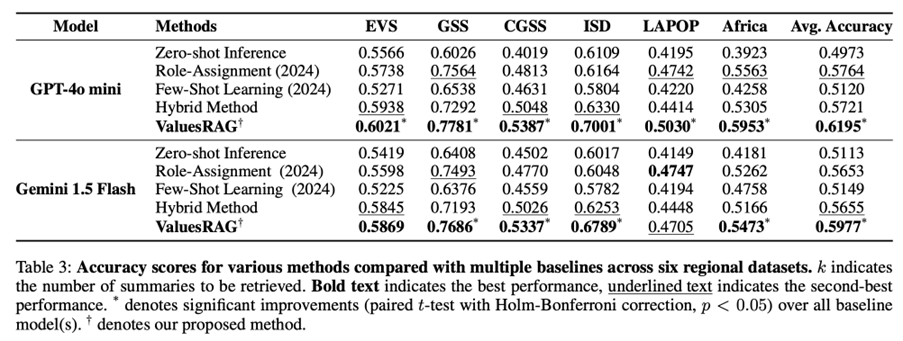
ValuesRAG consistently outperformed all baseline methods across regions. Using k=3, the framework achieved an average accuracy of 0.6195 with GPT-4o-mini and 0.5977 with Gemini-1.5 Flash, compared to baseline averages of 0.4973–0.5764.Improvements were particularly pronounced in the GSS (North America) and ISD(India), with accuracy gains of up to 12 percentage points over zero-shot inference.
Stratified Analysis by Region
Regional differences were observed in model performance. Higher gains were observed in regions with rich demographic overlap with WVS (North America, South Asia),where ValuesRAG achieved accuracies exceeding 0.77. In contrast, performance improvements were smaller but still significant in Afrobarometer and LAPOP datasets, reflecting more heterogeneous cultural patterns.
Optimal Retrieval Depth
The optimal retrieval depth was identified as k=3 across both models. At this depth, ValuesRAG balanced contextual breadth and retrieval precision, achieving the highest average performance. Increasing k to 10 diluted relevance and decreased accuracy, while restricting to k=1 reduced diversity and limited generalizability.

Conclusion
We propose ValuesRAG, a novel framework designed to advance cultural values alignment through context-aware reasoning. In contrast to prior methods that rely on fixed demographic labels or limited few-shot prompting, ValuesRAG dynamically retrieves and integrates contextually rich value summaries using adaptive retrieval, reranking, and In-Context Learning (ICL). Our contributions extend beyond the framework design to include a comprehensive evaluation across diverse, culturally and geographically representative test datasets. Extensive experiments demonstrate that ValuesRAG consistently outperforms existing approaches, effectively capturing complex cultural nuances, reducing biases,and generating contextually aligned responses.
in solving your problems with Enhans!
We'll contact you shortly!