

Author: Wonduk Seo (서원덕), Taesub Shin (신태섭),Hyunjin An (안현진), Dokyun Kim (김도균), SeunghyunLee (이승현)
AI Research,Enhans AI
Accepted by IEEE International Conference on Big Data (BigData) 2025 Industry Track
TL;DR
1. The paper introduces Q2K (Question-to-Knowledge), a multi-agent LLM framework that turns SKU matching into a process of generating and validating inspectable facts instead of relying on opaque similarity or single-shot judgments.
2. Q2K operates with three agents, including: Reasoning, Knowledge, and Deduplication,and a final Decision stage, all built on GPT-4o, OpenAI’s web-search API, and text-embedding-3-small for reasoning-trace retrieval over a knowledge repository of past cases.
3. On a 72k+ product-pair dataset (mostly F&B) collected with QA supervision, Q2K achieves 95.62% accuracy, outperforming several baselines including rule-based,zero-shot, few-shot, and web-search, while reducing redundant web calls via reasoning reuse.
4. In Enhans AI’s commercial pipelines, Q2K supports high-precision SKU mapping for tasks such as price monitoring, sourcing optimization, and bundle detection,providing transparent, reusable reasoning chains that are easier to audit and maintain than traditional rules or ad-hoc LLM prompts.
Abstract
Identifying whether two product listings refer to the same Stock Keeping Unit (SKU) is a persistent challenge in e-commerce,especially when explicit identifiers are missing and product names vary widely across platforms. Rule-based heuristics and keyword similarity often misclassify products by overlooking subtle distinctions in brand,specification, or bundle configuration. To overcome these limitations, we propose Question-to-Knowledge (Q2K), a multi-agent framework that leverages Large Language Models (LLMs) for reliable SKU mapping. Q2K integrates: (1) a Reasoning Agent that generates targeted disambiguation questions, (2) a Knowledge Agent that resolves them via focused web searches, and (3) a Deduplication Agent that reuses validated reasoning traces to reduce redundancy and ensure consistency. A human-in-the-loop mechanism further refines uncertain cases. Experiments on real-world consumer goods datasets show that Q2K surpasses strong baselines, achieving higher accuracy and robustness in difficult scenarios such as bundle identification and brand–origin disambiguation. By reusing retrieved reasoning instead of issuing repeated searches, Q2K balances accuracy with efficiency, offering a scalable and interpretable solution for product integration.
Introduction
The paper starts from a practical pain point in e-commerce: product titles are messy and identifiers (e.g., barcodes) are often missing. Slight wording changes, for instance: “Swiss-made,” “family pack,”variant names, or promo descriptors, can flip the equivalence judgment,making naive string matching unreliable. Rule-based pipelines are brittle and hard to maintain across categories; similarity models ignore fine-grained attribute logic; and retraining large domain-specific models is expensive and quickly becomes stale as catalogs evolve. Instead of fine-tuning a new model,we ask: Can we build a robust SKU mapping system on top of general-purpose LLMs, without retraining, by combining them with live web search and a reusable reasoning memory? Q2K is the answer: a multi-agent reasoning pipeline where the LLM is treated not as an oracle classifier, but as a controllable reasoning engine that (1) identifies what is ambiguous, (2) pulls in external evidence,and (3) reuses its own prior reasoning when appropriate. This shift moves SKU mapping away from a one-shot classification problem and toward a transparent,retrieval-augmented reasoning process.
Datasets and Methods

Datasets
The dataset is built through a semi-manual process with professional product sellers.
- For each base_product,annotators search a designated e-commerce site and collect candidate compared_product titles.
- They explicitly label which candidates are true matches and which are non-equivalent.
- Senior reviewers run supervision checks to correct noisy labels.
After minimal preprocessing, each instance is simply stored as:
(base_product, compared_product, y)
with y∈{0, 1} indicating SKU equivalence. The final dataset has ~72,250 product pairs, predominantly in the food & beverage domain.Manual checks suggest 3-5% label noise, largely from borderline cases such as origin emphasis or subtle bundle differences. This reflects realistic, noisy commercial conditions rather than a pristine benchmark.
Models and Retrieval.
- Agents: All Q2K agents use GPT-4o (temperature = 0) via API for deterministic, reproducible outputs.
- Web access: The Knowledge Agent uses the official OpenAI web-search API to fetch up-to-date product information.
- Embeddings: The knowledge repository of past reasoning traces is indexed with text-embedding-3-small, mapping questions and question-sets into a vector space.
- Similarity: Cosine similarity is used to compute how close a new concatenated question sequence is to stored ones, and a Top-5 retrieval operator R5(⋅) returns candidate traces for reuse.
Evaluation
Task: binary classification of SKU equivalence.
Metric: Accuracy, defined as

where y hat is the predicted label.
Baselines
All baselines use GPT-4o to isolate reasoning strategy rather than model capacity:
1. Rule-Based Matching: deterministic string normalization + brand dictionary + quantity/spec matching.
2. Zero-Shot Inference: LLM directly answers “same product or not,” with no examples.
3. Few-Shot Inference: LLM sees a small set of labeled examples before classifying new pairs.
4. Web-Search Inference: LLM has web snippets for both products appended to the prompt and makes a decision, but without structural decomposition or reuse.
Framework: Question-to-Knowledge (Q2K)

Q2K’s core idea: “Ask -> Gather -> Reuse ->Decide.” It is implemented via three agents plus a decision stage.
1. Reasoning Agent - Ask Better Questions
- Input: (Pb, Pc), the base and candidate product names.
- Output: a set of disambiguation questions Q={q1,…,qm} focused on attributes that matter for SKU equivalence.
- Questions are guided by 5 matching dimensions:

The agent is prompted to generate only as many questions as necessary, not a huge checklist,so the decomposition is targeted and efficient.
2. Knowledge Agent - Gather Inspectable Facts
- For each question qi,the agent queries the web and synthesizes a concise answer ai = Gk(qi,Pb, Pc).
- The outputs are short,self-contained rationales tailored to SKU comparison, not generic descriptions.
- Answers are grouped as A= {a1,…,am} and effectively form a mini “factsheet” for the product pair.
3. Deduplication Agent - Reuse Reasoning When Possible
- To avoid recomputing similar reasoning over and over, Q2K maintains a knowledge repository:
QDB = {(Q1,A1),…,(Qj, Aj)} where each Qj is a concatenated sequence of questions, and Aj the validated answers.
For a new pair, Q2K concatenates current questions into Qconcat, embeds it, and retrieves Top-5 similar traces R5(Qconcat).
The Deduplication Agent then judges whether these existing traces provide enough information(information gain) to decide the new case.
- If yes -> reuse the stored answers, skipping web search.
- If no -> trigger fresh Knowledge Agent calls and then store the new reasoning back into the repository.
4. Decision Stage - Make the Final Call
- The final agent takes:
- Pb,Pc
- Generated questions Q
- Answers A (reused and/or newly computed)
- It checks consistency across the five dimensions and outputs:
- A binary label (1 same SKU, 0 different SKU)
- A short, human-readable explanation.
This architecture makes every decision traceable: you can inspect which questions were asked, how they were answered, and which past reasoning was reused.
Experimental Results
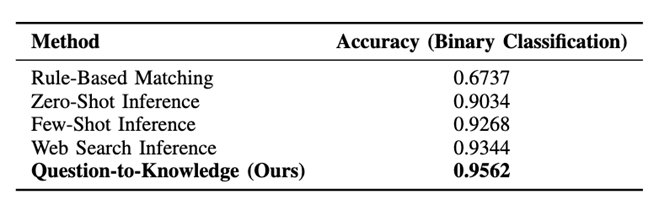
Main Experiment Result
- Rule-based methods underperform badly (~67.4%): they break on aliasing, promos, and subtle spec/quantity nuances.
- Zero-shot GPT-4o already does well (~90.3%) by leveraging semantic understanding, but fails when facts are missing.
- Few-shot improves to~92.7% by giving LLM concrete examples, but remains limited by example coverage.
- Web-search inference performs best among baselines (~93.4%), showing that real-time evidence matters, but with scattered, unstructured search, it incurs redundancy and inconsistent reasoning paths.
- Q2K reaches 95.62%, outperforming all baselines and improving efficiency by reusing reasoning across similar product families.
Ablation and Behavior Analysis

- The Reasoning Agent generates on average 1.4 questions per pair, with <20% of cases needing multiple questions, showing focused, not bloated, decomposition.
- The Deduplication Agent reuses reasoning in about 22% of comparisons, meaning nearly 1 in 5 product pairs are resolved without fresh web queries.
- This reuse not only cuts cost and latency but also preserves consistency - similar product families are judged with shared evidence and logic.
Overall, the experiments show that structured,retrieval-augmented multi-agent reasoning (Q2K) yields both higher accuracy and better efficiency than unstructured LLM + web-search prompts.
Conclusion
Q2K operationalizes a simple but powerful pipeline for SKU mapping:
Decompose the ambiguity → collect verifiable facts →reuse prior reasoning → make a transparent decision.
Instead of treating product mapping as pure string similarity or an opaque LLM classification problem, Q2K turns it into a question-to-knowledge process, built around three agents and a growing knowledge base of reasoning traces. The framework delivers:
- Higher accuracy (95.62%)than strong rule-based and LLM baselines.
- Interpretability, via explicit questions and evidence.
- Scalability and efficiency, by reusing prior reasoning and limiting unnecessary web calls.
For Enhans AI, this translates into more reliable product normalization, better price and assortment analytics, and a reasoning asset that can be continuously leveraged across clients and verticals.
in solving your problems with Enhans!
We'll contact you shortly!