

Author: WondukSeo, Juhyeon Lee, Junseo Koh, Hyunjin An, Jian Park, Seunghyun Lee, HaihuaChen, Yi Bu
AI Research, Enhans,Peking University, Fudan Univversity, University of North Texas
Pre-print Version,arXiv:2510.16635
Paper Link: https://arxiv.org/abs/2510.16635
TL;DR
1. This paper proposes MA-SAPO, a score-aware multi-agent framework for automatic prompt optimization that turns evaluation scores into interpretable reasoning artifacts, instead of treating evaluation as a black-box scalar.
2. MA-SAPO has a two-phase design: a Reasoning Phase (offline) that constructs reusable“reasoning assets” from scored prompt-response pairs, and a Test Phase (online)that retrieves and applies those assets to make evidence-grounded prompt edits.
3. The key idea is to couple metrics with structured explanations and diagnoses:agents explicitly explain why each metric score happened, identify weaknesses/trade-offs, then synthesize concrete edit directives, making optimization transparent, auditable, and controllable.
4. On HelpSteer1/2, MA-SAPO consistently improves multi-metric quality over single-pass prompting, RAG-style baselines, and prior multi-agent systems, while using only 2 calls at test time and far fewer output tokens than debate/iterative agent frameworks.
Abstract
Prompt optimization is an efficient alternative to retraining LLMs, but most methods optimize using only numerical feedback, offering limited insight into why prompts succeed or fail and often relying on expensive trial-and-error. MA-SAPO addresses this by converting metric outcomes into reusable reasoning assets via a multi-agent pipeline (explain, diagnoses, synthesize). At test time, it retrieves relevant assets and applies evidence-backed edits through an Analyzer, Refiner workflow.Experiments on HelpSteer1/2 show consistent gains across helpfulness,correctness, coherence, complexity, and verbosity, with strong efficiency and improved interpretability.
Introduction
LLM performance is highly sensitive to prompt phrasing and structure, making prompt optimization a practical alternative to fine-tuning. While prior work includes (i) single-pass strategies (CoT, role prompting, ToT/GoT variants, evolutionary prompting) and (ii) multi-agent frameworks (debate, critique loops, hierarchical planners), common gaps remain:
- Evaluation is often a black box: methods optimize a scalar score without explaining why the score is high/low.
- Edits are trial-and-error: repeated rewrites add cost and reduce controllability.
- Reasoning isn’t reusable: even when models “reason,” the insight isn’t stored as auditable artifacts that guide future edits.
- Interpretability +control are limited: users can’t easily understand trade-offs (e.g., verbosity vs. coherence) or apply targeted adjustments.
MA-SAPO reframes prompt optimization as score-aware reasoning + retrieval of reusable diagnostic knowledge.
Datasets and EvaluationSetting
Datasets
MA-SAPO is evaluated on the HelpSteer family, which provides prompt-response pairs with five human-annotated quality scores (0-4 scale):
- HelpSteer1: ~35.3k train / ~0.79k validation
- HelpSteer2: ~20.3k train / ~1.04k validation (richer annotations; ~29%multi-turn; includes preference signals)
HelpSteer2 train is used as the retrieval corpus for constructing reasoning assets.
Metrics
Five dimensions (each 0-4,normalized to [0,1]):
- Helpfulness, Correctness, Coherence, Complexity, Verbosity
- Overall score = average across the five normalized metrics.
Models
- Reasoning-asset construction (offline): OpenAI o4-mini (used only togenerate assets)
- Test-time optimization backbones: GPT-4o and LLaMA-3-8B-Instruct(temperature=0)
- Judge / evaluator: ArmoRM-Llama3-8B-v0.1 reward model scoring the five metrics
Retrieval:
- Sparse lexical retrieval: BM25 over prompt text
- Default top-k = 3 retrieved examples (shown best in ablations)
Framework: MA-SAPO
Core idea: Instead of “rewrite until the score improves,” MA-SAPO builds a memory of score-grounded reasoning and uses it to apply justified, targeted edits.
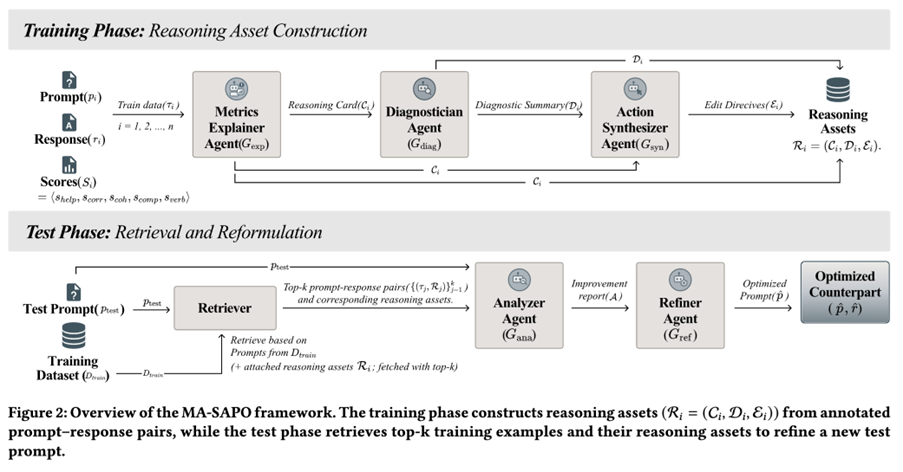
MA-SAPO consists of two stages:
1) Reasoning Phase (Training / Offline): Reasoning Asset Construction
Each training instance is a triplet: τᵢ = (prompt pᵢ, response rᵢ, scores Sᵢ)
Three agents run sequentially to produce reusable assets Rᵢ = (Cᵢ, Dᵢ, Eᵢ):
(a) Metric Explainer Agent (G_exp)
Produces a reasoning card Cᵢ explaining why each metric score was assigned and what would improve it.
(b) Diagnostician Agent (G_diag)
Produces a diagnostic summary Dᵢ identifying: root causes of weak metrics trade-offs across metrics (e.g., adding detail might increase verbosity but reduce coherence)
(c) Action Synthesizer Agent (G_syn)
Converts explanation + diagnosis into actionable edit directives Eᵢ(concrete “what to change” guidance). These assets are stored as semi-structured text, serving as the retrieval corpus for test-time optimization.
2) Test Phase (Online): Retrieval + Evidence-Grounded Optimization
Given a new prompt p_test:
(a) Retrieve top-k similar training examples with their reasoning assets:
{(τⱼ, Rⱼ)} for j=1..k
(b) Analyzer Agent (G_ana)
Compares p_test against retrieved examples and assets, producing an improvement report:
what’s unclear or under specified
what structure is missing
what trade-offs to avoid
which edits are supported by retrieved evidence
(c) Refiner Agent (G_ref)
Generates an optimized prompt p̂ using the Analyzer report, prioritizing evidence-backed directives (rather than arbitrary rewriting).
Finally, the optimized prompt p̂ is used to generate the optimized response r̂, and the judge model scores(p̂, r̂).
Baselines
Six baselines grouped by category:
Single-pass(no retrieval):
1. Direct Generation
2. Chain-of-Thought (CoT)
3. Role Assignment
Retrieval-augmented(no reasoning assets):
4. RAG (BM25 retrieval of exemplars, k=10)
Multi-agent frameworks:
5. MAD (Multi-Agent Debate)
6. MARS (Planner + Teacher/Critic/Student, iterative)
Experimental Results
Main Results
Across HelpSteer1 and HelpSteer2, MA-SAPO achieves the best average score across all five metrics for both backbones.
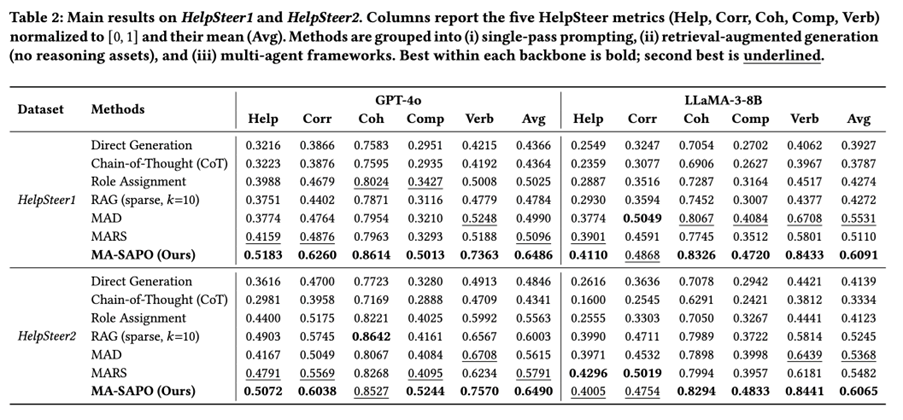
- HelpSteer1 (GPT-4o): MA-SAPO 0.6486 Avg, vs MARS 0.5096, RAG 0.4784
- HelpSteer2 (GPT-4o): MA-SAPO 0.6490 Avg, vs RAG 0.6003, MARS 0.5791
- HelpSteer1 (LLaMA-3-8B): MA-SAPO 0.6091 Avg, vs MAD 0.5531, MARS 0.5110
- HelpSteer2 (LLaMA-3-8B): MA-SAPO 0.6065 Avg, vs MARS 0.5482, RAG 0.524
Interpretation: MA-SAPO benefits from (i) retrieval plus (ii) explicit score-grounded reasoning assets that explain why an edit should be made.
Ablation Studies
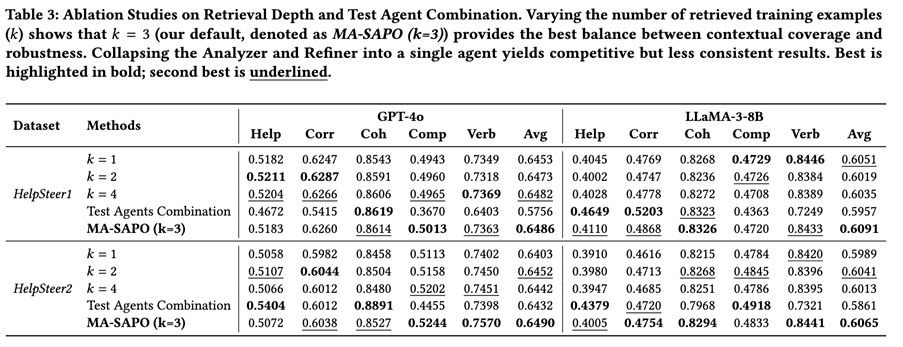
(1) Retrieval depth k
Finding: k=3 is the most consistent best setting—smaller k lacks diversity; larger k adds noise/conflicting signals.
(2) Merging Analyzer + Refiner into one agent
A single combined agent can be competitive on some metrics, but is less consistent overall. Conclusion:separating diagnosis (Analyzer) and execution (Refiner) improves reliability and maintains auditability.
Qualitative Analysis
Annotators: 14 experts (data scientists / AI engineers / grad students)
H1: Reasoning Quality (30 cases)
Compared MA-SAPO multi-agentreasoning vs a single-agent baseline on:
- usefulness, accuracy, consistency (1-5 Likert)
MA-SAPO improves all three;usefulness and accuracy show statistically significant gains.
H2: Directional Consistency (40 prompt pairs)
Measures whether optimized prompts preserve original intent (1-4 scale).
Result: Mean 3.36 / 4, with most ratings at 3-4, edits typically improve structure/clarity without drifting intent.
Conclusion
MA-SAPO introduces a practical approach to automatic prompt optimization by turning evaluation signals into retrievable, interpretable reasoning assets and using multi-agent analysis to apply evidence-grounded edits. It improves performance across HelpSteer1/2 and two backbones, while keeping test-time cost low and maintaining semantic intent.
in solving your problems with Enhans!
We'll contact you shortly!