

Author: WondukSeo*, Minhyeong Yu*, Hyunjin An, Seunghyun Lee
AI Research, Enhans
TL;DR
1. This paper introduces MARIC, a multi-agent framework that improves image classification by decomposing visual understanding into complementary perspectives instead of relying on single-pass VLM inference or training-heavy fine-tuning.
2. MARIC reformulates classification as collaborative reasoning: an Outliner Agent proposes targeted prompts from global context, Aspect Agents generate fine-grained descriptions across distinct visual dimensions, and a Reasoning Agent synthesizes them into a final label with an explicit reasoning trace.
3. A key design is reflective synthesis: before predicting the label, the Reasoning Agent revisits and critiques agent outputs to reduce inconsistencies and emphasize salient evidence, making decisions more robust and interpretable.
4. MARIC improves interpretability without model fine-tuning, producing structured reasoning traces that help explain why a label is predicted, while remaining scalable as an inference-time framework.
Abstract
Image classification has traditionally relied on parameter-intensive training with large annotated datasets. While vision–language models (VLMs) reduce the need for task-specific training, they often remain constrained by single-pass representations that fail to capture complementary aspects of visual content. We propose Multi-Agent based Reasoning for Image Classification (MARIC), a multi-agent framework that reframes classification as a collaborative reasoning process. MARIC uses an Outliner Agent to infer global theme and generate targeted prompts, Aspect Agents to extract fine-grained descriptions from distinct visual dimensions,and a Reasoning Agent to integrate these outputs through a built-in reflection step into a unified representation and final label. Experiments on four diverse image classification benchmarks demonstrate that MARIC significantly outperforms strong baselines, highlighting the effectiveness of multi-agent visual reasoning for robust and interpretable image classification.
Introduction
Despite decades of progress in image classification, moving from CNNs to Vision Transformers, state-of-the-art performance has often depended on large-scale labeled data and extensive fine-tuning. Vision–language models offer a compelling alternative by enabling zero-shot classification through text prompting, but many VLM-based approaches still rely on single-pass inference. This can miss complementary cues (e.g., background context vs. fine texture) and yields brittle predictions when visual evidence is ambiguous or partially occluded.
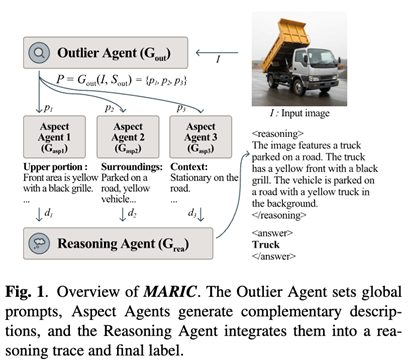
MARIC takes a different route: instead of treating classification as a one-shot generation problem, it decomposes visual reasoning into multiple specialized agents and uses reflective synthesis to aggregate evidence into a coherent decision. This design improves both accuracy and interpretability, while staying fully inference-time (no additional training required).
Datasets and Evaluation Setting
Datasets
We evaluate MARIC on four benchmarks spanning canonical, robustness, and medical settings:
- CIFAR-10: 10-class benchmark, sampled 100 images per class.
- OOD-CV: out-of-distribution robustness benchmark with 10 classes, sampled 100 images per class.
- Weather: 4-class weather condition dataset (sunrise / shine / rain /cloudy), 1,125 images.
- Skin Cancer: binary melanoma detection (healthy vs. cancerous), 87 images per class.
Models and Baselines
VLM backbones: LLaVA-1.5 7Band 13B (temperature 0).
Baselines:
Direct Generation: predict label from the image with minimal prompting.
Chain-of-Thought(CoT): prompt the model to reason step-by-step.
SAVR: single handcrafted reasoning prompt in one pass.
Framework: MARIC
Core idea: Improve image classification by explicitly collecting complementary evidence via specialized agents, then reflectively synthesizing it into a final decision.
MARIC consists of three stages:
1) Outliner Agent (Global Theme → Targeted Prompts)
Given image I, the Outliner Agent first identifies the global scene/theme and generates a set of targeted prompts that define what to look for in later stages. These prompts use a prefix–postfix structure:
- Prefix: focuses attention on a region/attribute
- Postfix: specifies the descriptive objective
This reduces redundancy and encourages orthogonal evidence extraction.
2) Aspect Agents(Fine-Grained, Complementary Descriptions)
Each Aspect Agent receives the image and one targeted prompt, producing a description dᵢ that focuses on a distinct visual dimension (e.g., texture, shape, background context). The goal is not verbosity, but coverage: multiple partial descriptions that collectively represent the image more faithfully than a single-pass explanation.
3) Reasoning Agent (Reflection-> Unified Reasoning Trace + Label)
The Reasoning Agent aggregates descriptions {d₁, d₂, d₃} and generates:
- a reasoning trace
- a final predicted label
Critically, MARIC includes an integrated reflection step: the Reasoning Agent explicitly revisits the Aspect outputs, critiques inconsistencies, filters noise, and emphasizes salient cues before deciding the label. This yields decisions that are both self-corrective and interpretable.
Experimental Results
Main Results
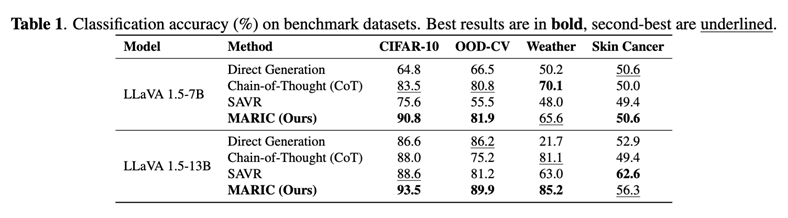
Across all four benchmarks,MARIC yields consistent gains over Direct Generation, CoT, and SAVR. In many cases, CoT produces long explanations that do not reliably translate to better accuracy, while single-agent prompting can miss subtle or complementary visualevidence. MARIC addresses both issues by forcing multi-perspective extractionand evidence integration.
Ablation Studies
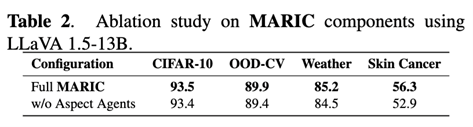
Removing Aspect Agents reduces performance—especially on more nuanced settings—confirming that MARIC’s improvements come from decomposition + complementary evidence, not just a stronger final prompt. Notably, even without Aspect Agents, the Outliner + reflective reasoning remains competitive, suggesting the global prompting + reflection mechanism is itself valuable.
Qualitative Analysis
A human study on CIFAR-10 samples evaluates MARIC’s aspect decomposition on three criteria:
- Aspect Relevance
- Aspect Diversity
- Description Accuracy
Results show strong average scores across all criteria, indicating MARIC’s agents produce meaningful,non-redundant aspects and descriptions that remain faithful to the image content.
Conclusion
MARIC shows that image classification can benefit substantially from collaborative, multi-agent reasoning rather than single-pass VLM inference or training-heavy pipelines. By combining targeted global prompting, complementary aspect descriptions, and reflective synthesis, MARIC delivers more accurate, robust, and interpretable predictions across diverse datasets. As an inference-time framework, it is easy to integrate with existing VLM backbones and offers a scalable direction for building reliable visual understanding systems.
in solving your problems with Enhans!
We'll contact you shortly!