

Author: Wonduk Seo, Juhyeon Lee, Hyunjin An, Seunghyun Lee, and Yi Bu
Enhans, Peking University
Proceedings of the 25th ACM/IEEE Joint Conference on Digital Libraries (JCDL)
Paper Link: Better by Comparison: Retrieval-Augmented Contrastive Reasoning for Automatic Prompt Optimization
TL;DR
1. This paper introduces CRPO (Contrastive Reasoning Prompt Optimization), are trieval-augmented framework that improves prompt quality by explicitly comparing high- and low-quality prompt–response examples, rather than optimizing prompts in isolation.
2. CRPO reframes prompt optimization as a contrastive reasoning task, where LLMs learn why certain prompts succeed or fail by reflecting on retrieved exemplars annotated with multiple human-centered quality metrics.
3. The framework proposes two complementary strategies: Tiered Contrastive Reasoning,which contrasts high-, medium-, and low-quality prompt–response pairs, and Multi-Metric Contrastive Reasoning, which integrates the best exemplars across helpfulness, correctness, coherence, complexity, and verbosity.
4. Experiments on the HelpSteer2 benchmark show that CRPO consistently outperforms Direct Generation, Chain-of-Thought prompting, and standard Retrieval-Augmented Generation across both GPT-4o and LLaMA-3-8B.
5. CRPO improves prompt quality without model fine-tuning, offering a practical,interpretable, and scalable solution for automatic prompt optimization in real-world LLM applications.
Abstract
Automatic prompt optimization has become essential for improving the reliability and usefulness of Large Language Models (LLMs). However, most existing approaches refine prompts through direct iteration or score-based optimization, without leveraging the rich comparative signals available in better and worse examples. To address this limitation, we propose Contrastive Reasoning Prompt Optimization (CRPO), are trieval-augmented framework that explicitly uses contrastive reasoning over prompt–response pairs. CRPO retrieves annotated exemplars from the HelpSteer2 dataset and enables LLMs to reflect on why certain prompts produce superior responses while others fail. Through two complementary strategies—tiered contrastive reasoning and multi-metric contrastive reasoning, CRPO synthesizes optimized prompts that integrate strengths across multiple evaluation dimensions. Experiments demonstrate that CRPO significantly outperforms strong baselines, highlighting the effectiveness of contrastive, retrieval-augmented reasoning for prompt optimization.
Introduction
Prompt quality plays a decisive role in the performance of Large Language Models. Small changes in phrasing can lead to substantial differences in correctness, helpfulness, and coherence. While recent work has explored automatic prompt optimization through soft prompt tuning, evolutionary search, or agent-based exploration, many approaches share a key limitation: they optimize prompts without learning from explicit comparisons between good and bad examples.
In practice, humans improve prompts by contrast, understanding why one prompt yields a better response than another. Existing automatic methods rarely capture this comparative reasoning. Moreover, many frameworks rely on handcrafted pipelines or focus narrowly on answer accuracy, overlooking broader human-centered dimensions such as interpretability and usability.
CRPO takes a different approach. Instead of treating prompt optimization as a single-path refinement problem, it frames it as a contrastive reasoning task grounded in retrieved exemplars. By comparing prompts and their resulting responses across multiple quality dimensions, CRPO enables LLMs to reason about failure modes and success patterns explicitly,leading to more robust and interpretable prompt optimization.
Datasets and Evaluation Setting
Datasets
CRPO is evaluated on the HelpSteer2 dataset, a large-scale benchmark designed for studying prompt optimization and response quality. The dataset contains over 20,000 training examples and a held-out validation set, where each prompt–response pair is annotated by humans along five dimensions:
- Helpfulness – how well the response addresses the prompt
- Correctness – factual accuracy and absence of errors
- Coherence – clarity and logical consistency
- Complexity – depth and level of expertise demonstrated
- Verbosity – appropriateness of response length
These fine-grained annotations make HelpSteer2 particularly suitable for contrastive reasoning.

Models andEvaluation
LLMs: GPT-4o and LLaMA-3-8B
Retrieval: Sparse retrieval over prompt text to obtain top-k reference examples
Evaluation: A multi-objective reward model scores generated responses along the five HelpSteer2 dimensions,which are normalized and averaged for comparison
Framework: CRPO
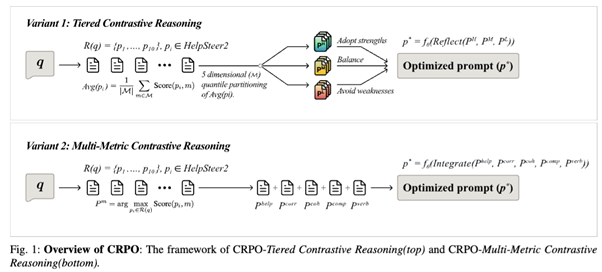
Core idea: Improve prompts by explicitly reasoning over contrasts between better and worse prompt–response pairs.
CRPO consists of two main stages: retrieval of reference exemplars and contrastive reasoning-based prompt synthesis.
1.Retrieval of Reference Prompt–Response Pairs
Given an input query, CRPO retrieves a set of relevant prompt–response pairs from the HelpSteer2 training set. Importantly, both the prompt text and the generated response are used,allowing the model to reason about how prompt formulation affects output quality across multiple dimensions.
2.Contrastive Reasoning Strategies
CRPO introduces two complementary optimization variants:
(a) Tiered Contrastive Reasoning Retrieved examples are grouped into high-, medium-, and low-quality tiers based on their overall annotation scores. The model is prompted to: (1) Avoid weaknesses observed in low-quality examples, (2) Adopt strengths from high-quality examples, and (3) Use medium-quality examples as stabilizing references.
This structure prevents overfitting to extreme cases while encouraging consistent improvement.
(b) Multi-Metric Contrastive Reasoning Instead of grouping by overall quality, this variant selects the best exemplar for each evaluation dimension (helpfulness, correctness, coherence,complexity, verbosity). The model then integrates complementary strengths across these dimensions into a single optimized prompt.
Experimental Results
Main Results
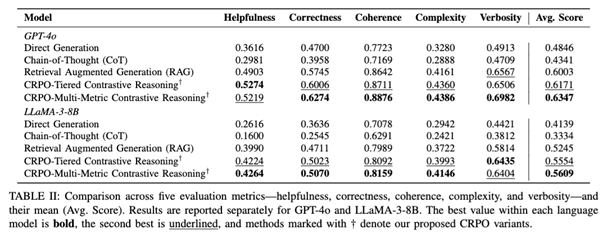
Across both GPT-4o and LLaMA-3-8B, CRPO consistently outperforms:
- Direct Generation, which lacks external grounding
- Chain-of-Thought prompting, which increases verbosity without improving factual quality
- Standard Retrieval-Augmented Generation, which retrieves examples but does not reason over contrasts
Both CRPO variants achieve higher average scores across all five evaluation dimensions, with multi-metric contrastive reasoning generally yielding the strongest overall performance.
Ablation Studies
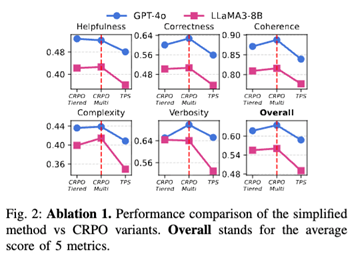
Contrastivevs. Retrieval-Only: Using only top-ranked retrieved prompts without contrastive reasoning leads to noticeably worse performance, confirming that CRPO’s gains stem from reasoning, not retrieval alone.
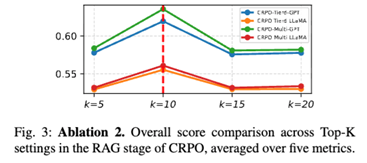
Effect of Retrieval Size: Performance improves with moderate retrieval sizes but degrades when too many examples are included, indicating a trade-off between evidence diversity and reasoning clarity.
Conclusion
CRPO demonstrates that prompt optimization benefits significantly from comparison, not just refinement. By explicitly reasoning over high- and low-quality prompt–response pairs and integrating insights across multiple human-centered metrics, CRPO produces prompts that are more robust, interpretable, and aligned with user intent.Unlike methods that rely on fine-tuning or rigid optimization pipelines, CRPO operates entirely at inference time and can be easily integrated into existing LLM workflows. This makes it a practical and extensible framework for improving prompt quality in real-world applications, from conversational agents to decision-support systems.
in solving your problems with Enhans!
We'll contact you shortly!