

In enterprise environments, documents remain the most common form of data creation.
However, as the volume of documents grows, the cost of retrieving accurate information increases, and those documents remain difficult to integrate into AI systems.
This article explains how unstructured enterprise documents can be structured and transformed into ontology based knowledge assets, focusing on document understanding and data representation. This is the first article in a three part series on ontology, and it concentrates on the foundational layer: document recognition and structuring.
Structural Limitations of Document Search
The challenge of finding correct information in large document collections
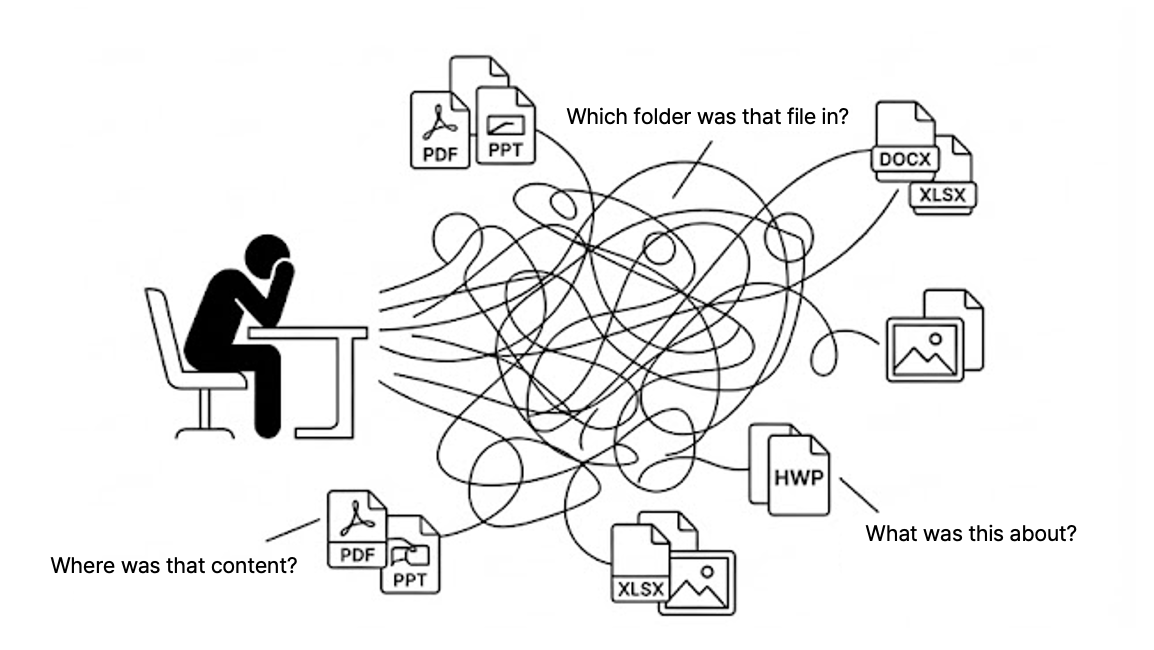
This project began with a document search system request from a large manufacturing enterprise. The company had a significant volume of internal documents used by manufacturing engineers, but those documents were distributed across multiple storage systems, making it difficult to locate specific information efficiently.
A typical document search process relies heavily on human memory. Users navigate folders based on recollection, open files based on file names, and manually scroll through documents to locate relevant sections. If the desired information is not found, the process is repeated across multiple documents.
As the number of documents increases, this approach becomes increasingly inefficient. Addressing this limitation was the starting point for developing a document search solution.
Search Performance Depends on Data Structure
After implementing a document search system, we analyzed its results by integrating them with an ontology system. The ontology system at Enhans processes text inputs by identifying entities and relationships and storing them as a structured graph.
Through this analysis, it became clear that document search performance is not primarily limited by search algorithms themselves, but by how unstructured documents are transformed into structured knowledge. When documents are represented as structured entities and relationships, it becomes possible to connect context across multiple documents and retrieve information with higher precision.
This approach extends beyond single document retrieval and enables semantic connections across distributed enterprise documents, which is particularly effective in enterprise environments.
Structural Complexity of Enterprise Documents
Enterprise documents exhibit a high degree of structural complexity.
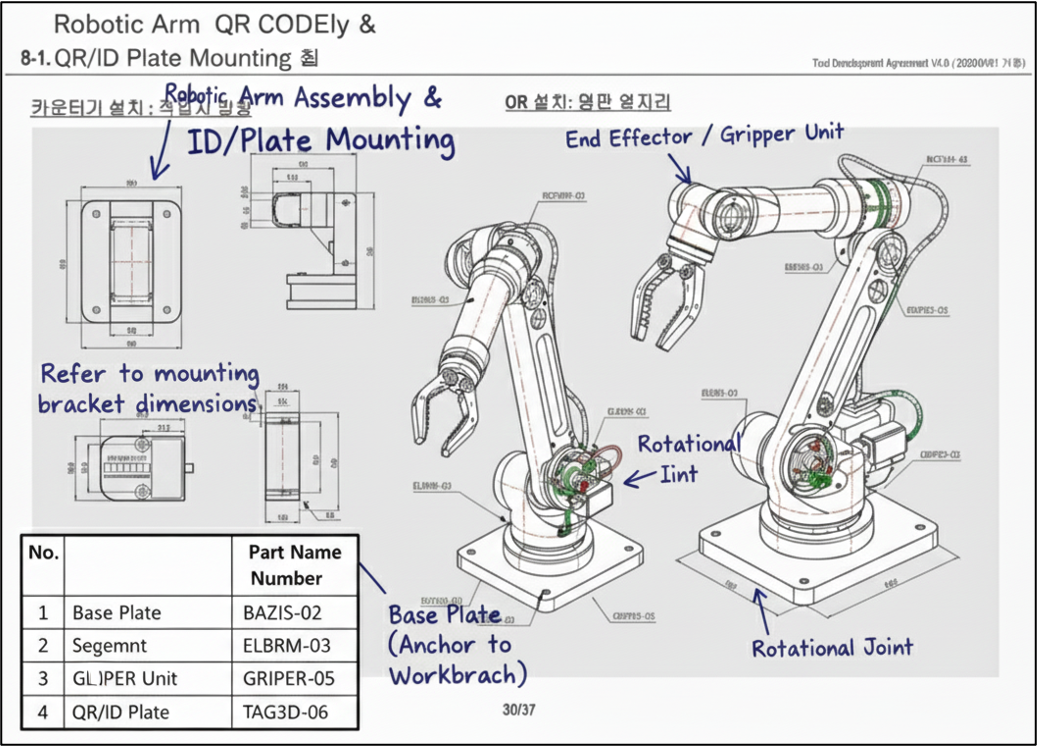
In manufacturing documents, a single file may contain text, engineering diagrams, images, and parts tables. It is common to see mixed languages, handwritten annotations, and product identifiers where even a single character error is unacceptable. Rotated or non linear text frequently appears in design drawings.
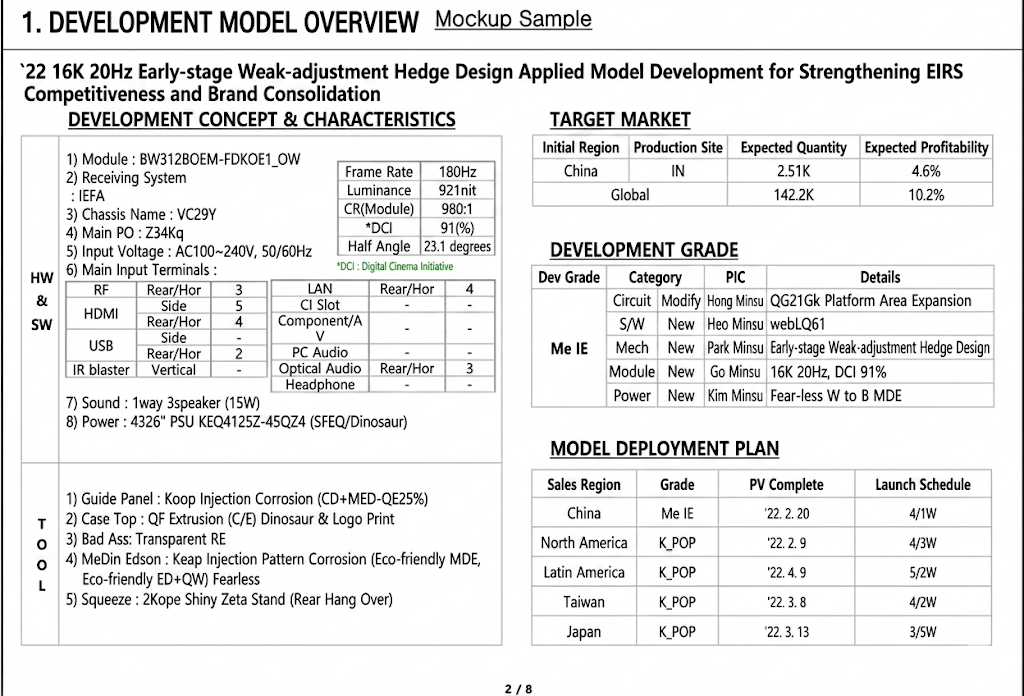
In other cases, a single slide may contain multiple tables, nested tables, or tables that depend on external contextual information. Although these tables appear structured, they do not conform to fixed schemas, making traditional database storage inefficient and costly to maintain.
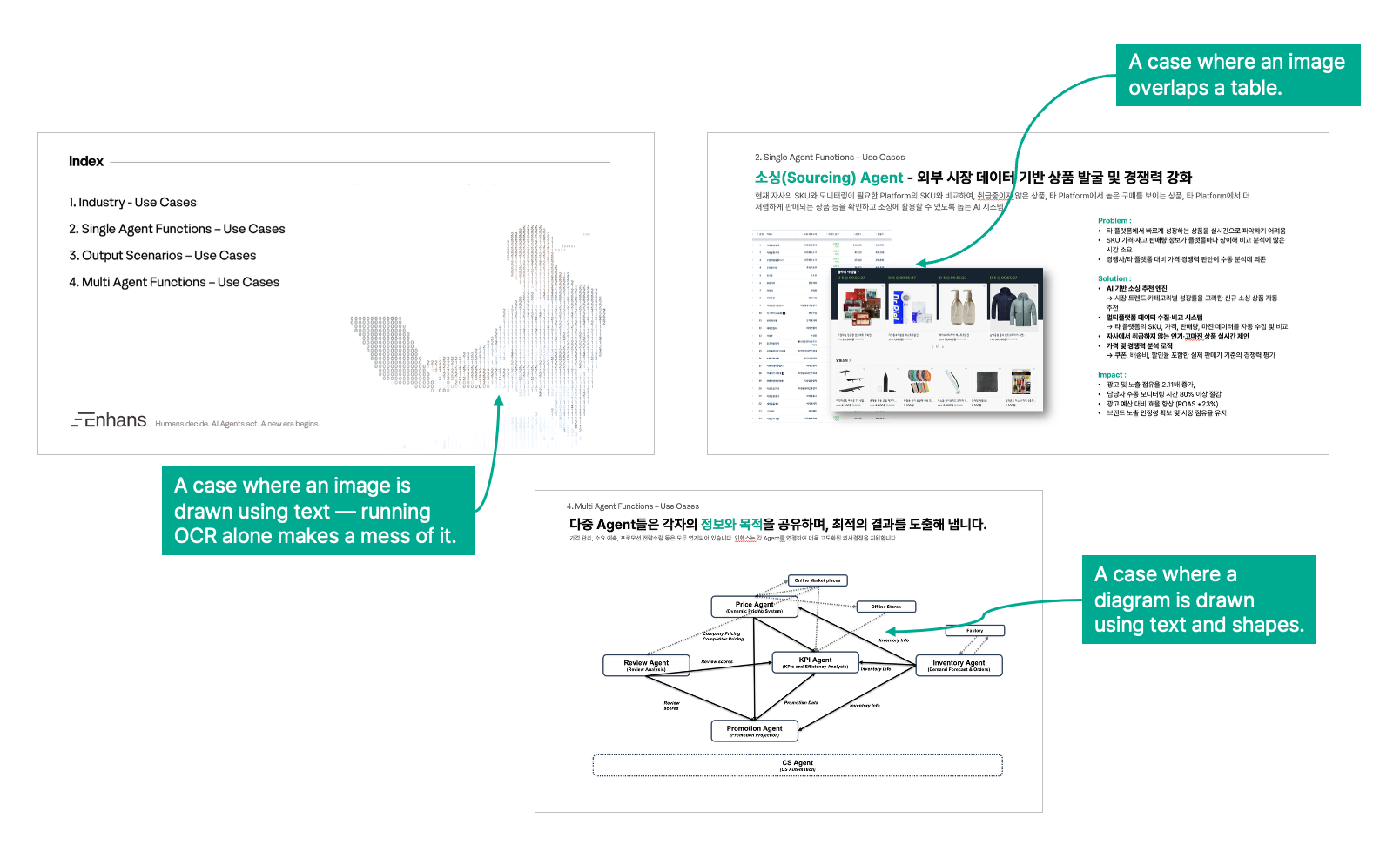
Enterprise documents also have minimal formatting constraints. Diagrams may be represented using numeric symbols, objects may overlap for emphasis, and conceptual models are often expressed using shapes rather than text. These patterns are common in real world enterprise environments.
As a result, enterprise documents are among the most abundant data sources but remain one of the most difficult data types to integrate into AI systems.
A Document Understanding Pipeline for Unstructured Data
To address these challenges, we designed a document understanding pipeline that goes beyond traditional OCR based approaches and focuses on interpreting the full document structure.
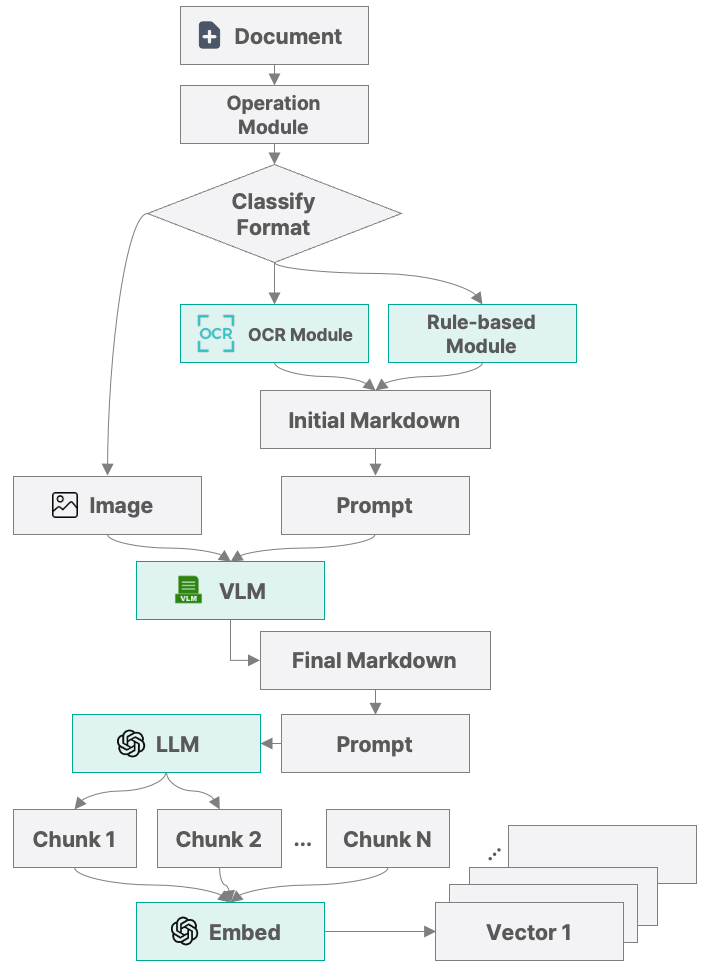
When a document is uploaded, it is routed to either an OCR module or a rule based transformation module depending on its format. The initial output is stored as a markdown representation of recognized text. The original document is then converted into images and passed, along with the initial markdown output, to a vision language model. At this stage, user intent can be injected through prompts.
The second stage output is an enriched markdown document that includes recognized text, table structures, and image descriptions aligned with the specified intent. This output becomes the primary input for ontology processing and embedding generation. The document is further segmented into semantic chunks using a large language model, and each chunk is converted into vector embeddings for use in a vector database.
This pipeline is model agnostic by design. OCR, vision language models, and large language models can be deployed using either open source local models or commercial APIs. Performance improvements can be achieved through modular replacement, allowing continuous integration of the latest models without rearchitecting the system.
Incorporating Human Reading Intent into Document Understanding
Document understanding quality depends not only on recognition accuracy but also on how well the system reflects human reading behavior.
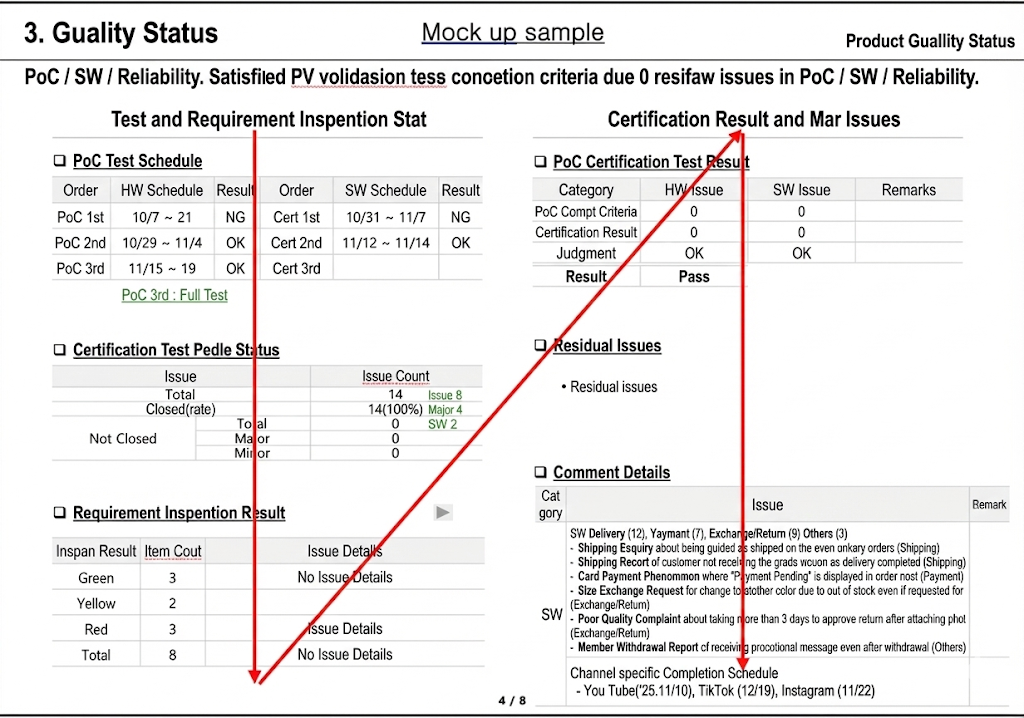
For example, when a slide contains two vertical columns of tables, humans typically read the left column first, followed by the right. Without guidance, a model may process rows sequentially instead. While technically valid, such output does not reflect user intent.
By accepting prompts such as "process this document column first," the pipeline can adjust recognition order to align with human expectations.
Similarly, merged table cells are common in enterprise documents but are not natively supported by markdown. This limitation is addressed by post processing with vision language models and HTML insertion. Images are not ignored but are converted into descriptive text, enabling queries based on visual content.
Transforming Documents into Ontology Based Knowledge
The outputs of document understanding are converted into structured knowledge using ontology rules.
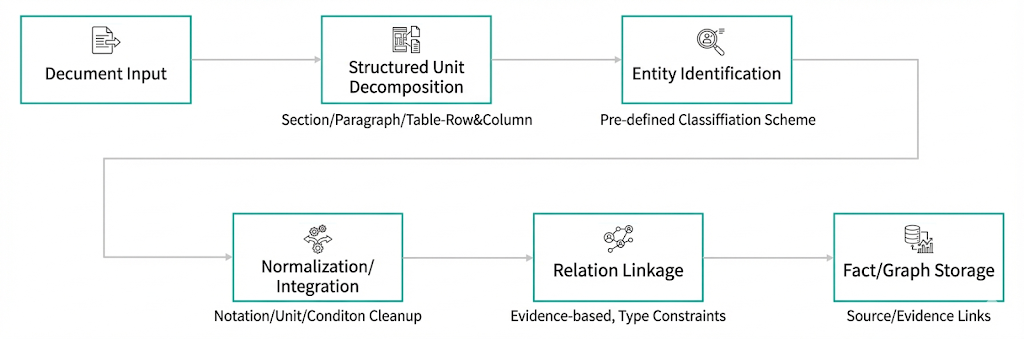
Documents are decomposed into structured units such as sections, paragraphs, tables, rows, and columns. Entities are identified based on predefined classification schemas. Notation, units, and conditions are normalized, and relationships are derived from document evidence. The final output is stored as facts and graphs, with each element linked to its original source and supporting evidence.
The goal is not summarization, but knowledge representation where conditions and evidence are preserved. This enables traceability and verification of AI generated responses.
Ontology Based Retrieval versus RAG
When large language models or AI agents require external knowledge, the retrieval method directly affects output quality.
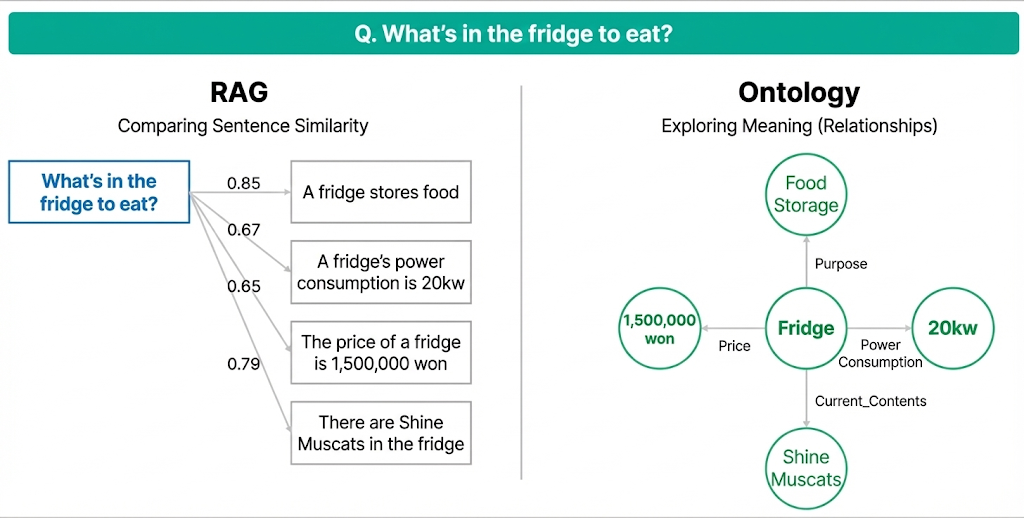
Retrieval Augmented Generation relies on sentence similarity to fetch relevant text. While effective for many use cases, it may introduce information that is lexically similar but semantically irrelevant to the query.
Ontology based retrieval operates on entities and relationships rather than sentences. By traversing defined relationships, the system retrieves information that aligns directly with the intent of the query, producing more consistent and precise results.
When applied to documents, this approach creates a knowledge graph composed of entities, relationships, and evidence. Queries are resolved through relationship based traversal rather than keyword matching.
Connecting Multiple Documents through a Knowledge Graph
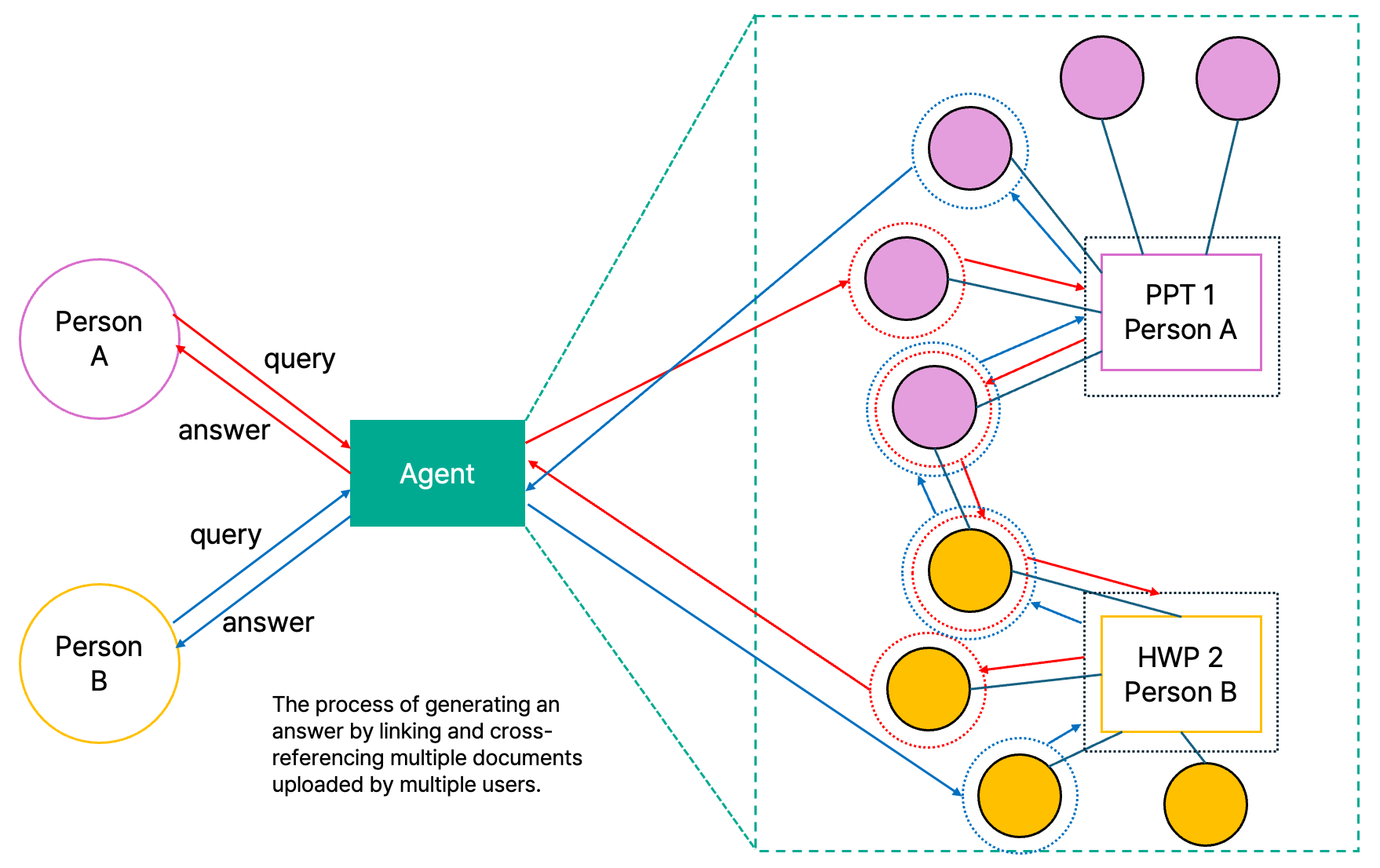
As multiple documents are uploaded, extracted entities and relationships are unified into a single ontology graph. When a query is issued, the AI agent navigates this graph, following related nodes and evidence links across different documents, formats, and authors.
This architecture is particularly effective in collaborative enterprise environments. Documents uploaded by different individuals can be connected through shared ontology definitions, enabling organization wide knowledge access rather than isolated personal search.
From Searchable Documents to Knowledge Assets
Enterprise documents will continue to accumulate. As they do, information retrieval becomes more difficult unless the underlying data representation changes.
The critical question is not how to search documents more efficiently, but whether the knowledge contained within documents can be transformed into reusable structured assets.
By reconstructing unstructured documents into semantic units and connecting them through ontology based knowledge graphs, queries shift from folder navigation to fact and evidence retrieval.
Ontology provides a practical and scalable approach for converting unstructured enterprise data into durable knowledge assets. In the next article, we will explore how this ontology foundation can be used to advance AI systems and autonomous agents.
in solving your problems with Enhans!
We'll contact you shortly!