

Author: Wonduk Seo (서원덕), Hyunjin An (안현진), Seunghyun Lee (이승현)
AI Research, Enhans AI
Accepted by Nineteenth ACM International Conference on Web Search and Data Mining (WSDM)
TL;DR
- The paper introduces AMD (Agent-Mediated Dialogic), a multi-agent framework for query expansion in Information Retrieval.
- AMD is evaluated on 8 datasets (6 from BEIR and 2 from TREC Deep Learning 2019/2020) using Qwen2.5-7B-Instruct for generation and multilingual-e5-base for dense retrieval. It supports sparse, dense, and RRF fusion retrieval strategies.
- The framework enables Enhans AI’s commercial agents to better capture user intent by reformulating user queries into multiple targeted sub and generating enriched query representations, thus improving web search quality and relevance.
- It supports their dynamic retrieval platform (sparse, dense, and fusion pipelines) by supplying richer query embeddings or expanded terms that enhance retrieval performance, enabling the agents to deliver higher-value insights and differentiating features to clients.
Abstract
Query expansion is widely used in Information Retrieval (IR) to improve search outcomes by supplementing initial queries with richer information. While recent Large Language Model (LLM) based methods generate pseudo-relevant content and expanded terms via multiple prompts, they often yield homogeneous, narrow expansions that lack the diverse context needed to retrieve relevant information. In this paper, we propose AMD: a new Agent-Mediated Dialogic Framework that engages in a dialogic inquiry involving three specialized roles: (1) a Socratic Questioning Agent reformulates the initial query into three sub-questions, with each question inspired by a specific Socratic questioning dimension, including clarification, assumption probing, and implication probing, (2) a Dialogic Answering Agent generates pseudo-answers, enriching the query representation with multiple perspectives aligned to the user’s intent, and (3) a Reflective Feedback Agent evaluates and refines these pseudo-answers, ensuring that only the most relevant and informative content is retained. By leveraging a multi-agent process, AMD effectively crafts richer query representations through inquiry and feedback refinement. Extensive experiments on benchmarks including BEIR and TREC demonstrate that our framework outperforms previous methods, offering a robust solution for retrieval tasks.
Introduction
Classical query expansion in IR, most notably PRF variants, improves retrieval by appending terms mined from top-ranked documents, but its static term selection tends to amplify a narrow slice of the user’s need, limiting diversity and depth. Recent LLM-based methods broaden the design space: Q2D generates pseudo-documents, Q2C uses Chain-of-Thought reformulations, and GenQREnsemble/GenQRFusion produce or fuse keyword-driven variants. Yet these methods frequently converge to homogeneous expansions, lack explicit mechanisms to challenge assumptions or explore implications, and rarely include a principled feedback step to prune redundancy or noise. As a result, even when they help, they often under-express the multifaceted nature of intent and can be computationally heavy (e.g., fusing many prompt variants).
To overcome these gaps, the paper proposes AMD (Agent-Mediated Dialogic) query expansion, which couples Socratic decomposition with dialogic answering and reflective filtering. A Socratic Questioning Agent rewrites the initial query into three targeted sub-questions (clarification, assumption probing, implication probing). A Dialogic Answering Agent then generates pseudo-answers to these sub-questions, enriching the query with multiple, intent-aligned perspectives. Finally, a Reflective Feedback Agent evaluates and rewrites the answers to keep only informative, non-redundant content. The resulting expansions are designed to be diverse and filtered, and can be integrated with sparse, dense, or fusion pipelines, aiming for both effectiveness and efficiency.
Datasets and Methods
Datasets.
AMD is evaluated on 8 benchmarks: six BEIR subsets: Webis-Touché2020 (argument retrieval), SciFact (scientific claim verification), TREC-COVID (COVID-19), DBPedia-Entity (entity-centric), SCIDOCS (scientific citation context), and FIQA (financial Q&A), plus TREC Deep Learning Passage tracks 2019 and 2020. This mix spans different domains and query/document granularities, stress-testing generality.
Models.
The agent pipeline uses Qwen2.5-7B-Instruct (temperature 0.5, max length 512) for generation. For dense retrieval, it uses multilingual-e5-base to embed queries and documents with cosine similarity. As a sparse baseline, it adopts BM25 via the bm25s implementation (SciPy-based, fast sparse scoring). Baselines include Q2D, Q2C, GenQREnsemble, and GenQRFusion, run in their original configurations.
Aggregation with expanded queries.
AMD supports three integration modes:
- Sparse concatenation. Replicate the original query 3 times and append all refined pseudo-answers; use separators (e.g., [SEP]). This boosts core signals while injecting curated context
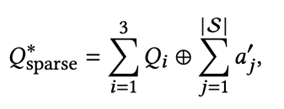
- Dense fusion. Form a final query embedding as a weighted sum: 0.7 × embedding(original query) + 0.3 × mean(embeddings of refined answers). This follows prior weighted aggregation practice and encodes expansions directly.
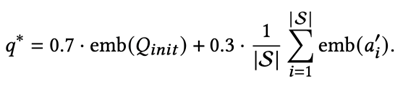
- RRF fusion. Treat each refined answer as a separate expanded query, retrieve independently, then Reciprocal Rank Fuse scores with k=60 to dampen tail ranks; rerank by summed fused scores.

Framework (Agent-Mediated Dialogic AMD)

Socratic Questioning Agent.
In a single LLM pass, generate three sub-questions, each tied to a Socratic dimension:
- Clarification: sharpen or disambiguate the user’s intent.
- Assumption probing: surface hidden premises and alternative framings.
- Implication probing: explore downstream effects, related facets, or consequences.
This step broadens the search space structurally, not just by paraphrase.
- Dialogic Answering Agent. For each sub-question, generate a pseudo-answer that acts like a compact, focused surrogate document. Answers are produced in parallel (single inference over all sub-questions), emphasizing efficiency while capturing distinct perspectives that enrich the initial query semantics.
- Reflective Feedback Agent. Evaluate the three (question, answer) pairs in context of the original query and rewrite answers to filter vague, redundant, or off-target content, while retaining informative, intent-aligned evidence. Importantly, this agent is not finetuned, underscoring practicality and portability. The refined set of answers becomes the expansion pool that feeds the chosen retrieval integration (sparse/dense/RRF).
Experimental Results

Sparse retrieval (BM25-based).
AMD achieves the strongest BEIR average and improved TREC DL aggregates. For example, on BEIR, AMD’s average nDCG@10 is 0.4352, surpassing BM25 (0.3672) and also Q2C (0.4147) and Q2D (0.4193). It posts consistent wins on individual sets like Webis (0.3896) and SciFact (0.7021). On TREC DL’19 and ’20 (averaging nDCG@10 and R@1000), AMD improves combined scores (e.g., DL’19 0.5870, DL’20 0.5818), edging out Q2D/Q2C and markedly exceeding BM25.
Dense retrieval (E5-base).
AMD again leads on the BEIR average (0.4707) and strengthens TREC DL performance (DL’19 0.5752, DL’20 0.5847) relative to strong LLM baselines. The dense weighted-fusion design (0.7/0.3) helps retain the anchor of the original intent while injecting curated multi-perspective signals.
RRF fusion (BM25-based).
Compared to GenQRFusion (which fuses rankings from up to 10 keyword-prompted queries), AMD obtains a higher BEIR average (0.4113 vs 0.3897) and better combined scores on TREC DL’19 (0.5041) and DL’20 (0.4819). The takeaway is that fewer but higher-quality expansions, curated by the reflective step, can beat broader but noisier ensembles while reducing computation.

Ablation (feedback on/off).
Removing the Reflective Feedback Agent consistently hurts average scores and increases variability. For instance, in the sparse setting, BEIR average drops from 0.4352 (with feedback) to 0.4295 (without). Similar gaps appear for dense (0.4707 to 0.4658) and RRF (0.4113 to 0.4147 on BEIR but with weaker TREC-DL). Even without feedback, AMD remains competitive or superior to baselines, but the feedback stage provides steady, measurable gains and stabilizes performance across datasets.
Conclusion
AMD operationalizes a simple but powerful idea: structure first (Socratic), diversify by design (dialogic answers), then select (reflective feedback). This yields expansions that are not only diverse but also filtered and intent-aligned, translating into consistent improvements across sparse, dense, and fusion retrieval pipelines on BEIR and TREC DL. The framework is practical (single-pass generation for questions/answers, non-finetuned feedback agent) and modular (plug-and-play with common retrievers and fusion schemes).
The main limitation is residual noise because the feedback agent is not finetuned for evaluation/rewriting; some irrelevant content can persist. Future work aims to finetune the feedback component and perform deeper qualitative audits of each agent’s contribution (e.g., which Socratic dimensions most help which domains), potentially unlocking larger gains and more interpretable, domain-aware expansions.
in solving your problems with Enhans!
We'll contact you shortly!