

알파고 대국 10주년, 같은 장소에서 Enhans는 다른 장면을 만들었습니다. 대결의 자리였던 그곳에서 이제 AI는 협업자가 되었습니다.
이세돌 9단과의 대화에서 자연스레 사용자의 관심사를 찾아냈고, 에이전트들이 스스로 바둑 앱 기획을 시작했습니다. 코드 한 줄 입력하지 않고도 단 18분 만에, 앱이 완성되었습니다.
명령 없이 시작된 실행, 이게 가능했던 이유는 에이전트들이 협업하는 방식, 바로 AI OS에 있었습니다.
에이전트가 늘수록 시스템은 왜 불안정해지는가
여러 에이전트를 연결하면 복잡한 작업이 가능해질 것처럼 보입니다. 하지만, 실제 엔터프라이즈 환경에서는 에이전트가 많아질수록 통신이 복잡해지고, 체인이 길어질수록 흐름이 끊기는 문제가 발생합니다.
대부분의 멀티 에이전트 시스템은 에이전트 간 직접 호출 방식으로 작동합니다. A가 B를 호출하고, B가 C를 호출하는 구조입니다. 에이전트가 3개일 때는 가능한 방식입니다. 5개, 10개 또는 그 이상으로 늘어나면 한 에이전트의 실패가 연쇄적으로 전파되고, 오류가 발생해도 정확한 원인 추적이 어렵습니다.
Enhans는 이러한 문제를 해결하기 위해 새로운 프로토콜부터 직접 설계했습니다.
Pheromone Protocol: 신호를 남기면 에이전트가 스스로 반응한다
Enhans는 군집 지능(Swarm Intelligence)에서 착안했습니다. 군집 지능은 개별 개체들이 상호작용을 통해 전체적으로 지능적인 행동을 만들어내는 현상입니다. 대표적인 예로는 개미 군집이 있습니다. 먹이를 발견한 개미가 페로몬을 남기면, 다른 개미들이 그 신호를 감지하고 스스로 반응합니다. 중앙 지령 없이도 협업이 이루어집니다.
Enhans는 이 원리를 에이전트 통신에 그대로 적용했습니다. 어떤 파일에 내용이 변경되면, 그 파일 내용을 프롬프트로 활용하는 LLM 추론이 자동으로 발생합니다. 이 규칙 위에서 에이전트 간 모든 작업이 수행됩니다.
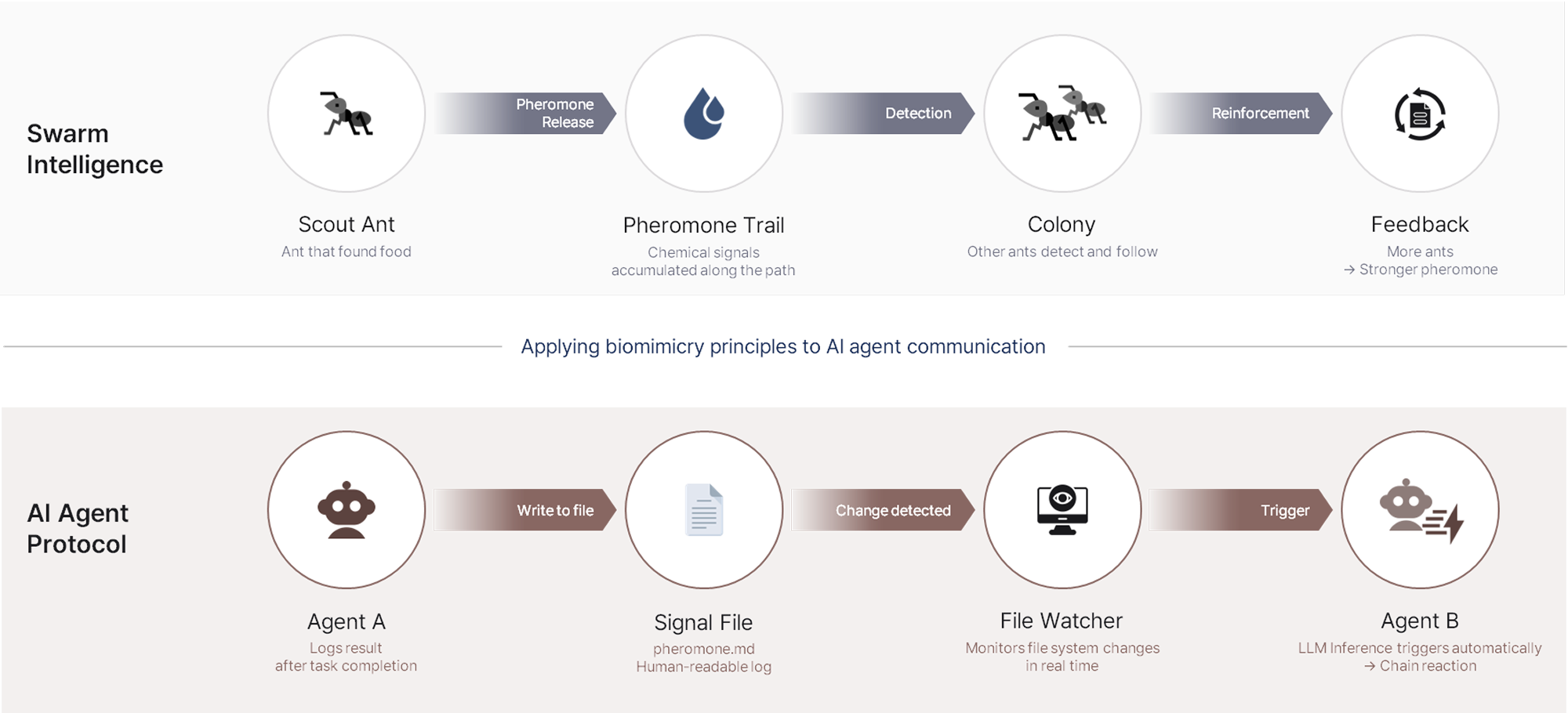
에이전트 A가 작업을 완료하면 결과를 파일(pheromone.md)에 기록합니다. File Watcher가 변경을 실시간으로 감지하고, 해당 파일을 읽은 에이전트 B의 LLM 추론이 자동으로 트리거됩니다. 에이전트들은 서로를 직접 호출하지 않습니다. 오직 파일이라는 환경에 신호를 남기고, 그 신호에 반응합니다.
실제 시연 현장, 이렇게 작동했습니다
이세돌 9단의 시연 현장에서 바둑 앱 제작은 이렇게 작동했습니다.
사용자 요청이 들어오면 OS Agent가 파싱해 task.md에 기록합니다. PM Agent가 이를 감지해 plan.md를 작성합니다. Design Agent가 plan.md를 읽고 design.md를 만듭니다. Coding Agent가 design.md를 기반으로 코드를 구현합니다. OS Agent가 최종 결과를 사용자에게 전달합니다. 각 단계는 모두 파일 기반 신호로 연결됐습니다.
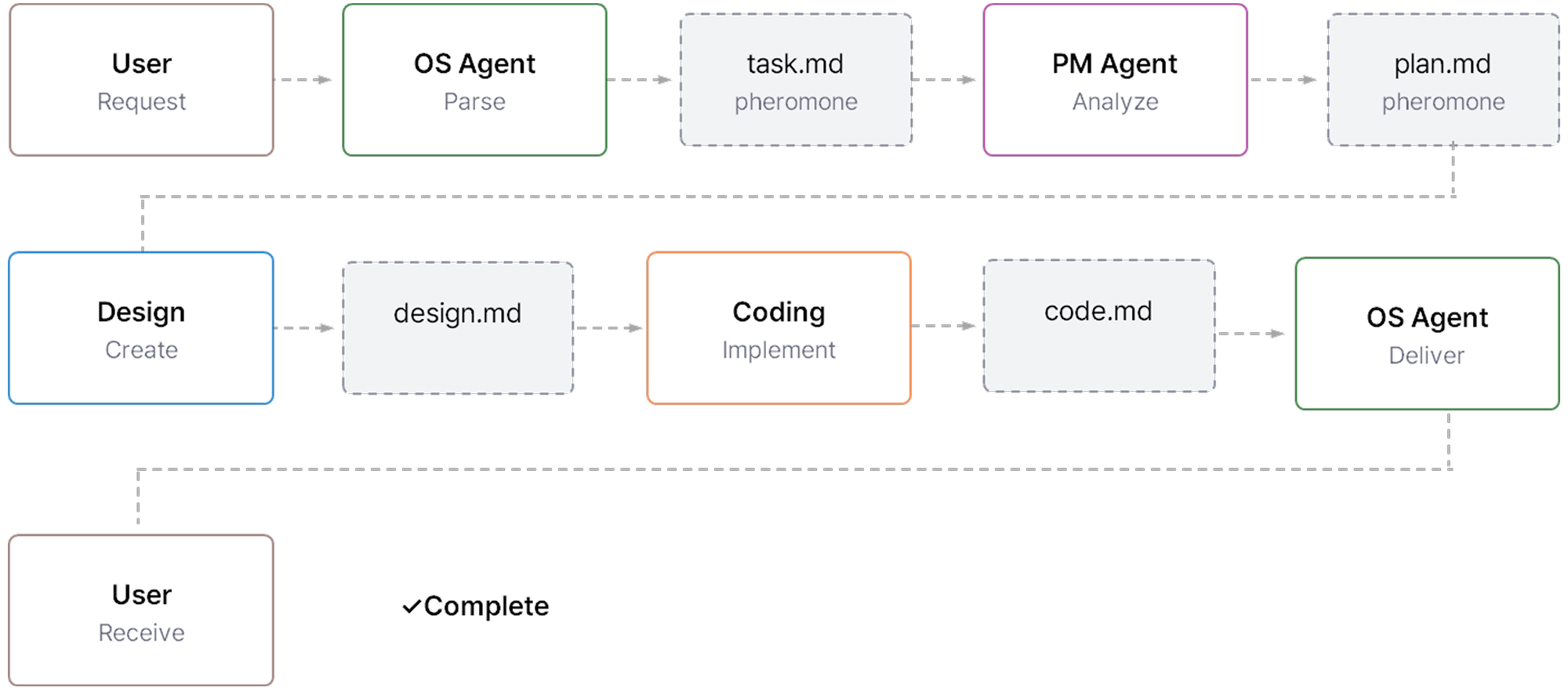
이 프로토콜의 장점은 별도의 메시지 브로커, 데이터베이스, API 서버가 필요 없다는 것입니다. 마크다운 파일이 그대로 로그가 되어 사람이 직접 읽을 수 있고, 시스템 재시작 후 상태 복구도 가능합니다.
에이전트 수가 늘어나도 구조가 복잡해지지 않습니다. 오히려 에이전트의 활동이 많아질수록 환경에 정보가 누적되어 시스템 전체의 학습 효과가 발생합니다.
3 Side Brain: 에이전트 하나가 추론, 행동, 기억을 모두 가진다
다음으로는 각 에이전트 내부가 설계된 방식입니다. Enhans는 에이전트를 세 가지 Brain 타입으로 규격화했습니다.
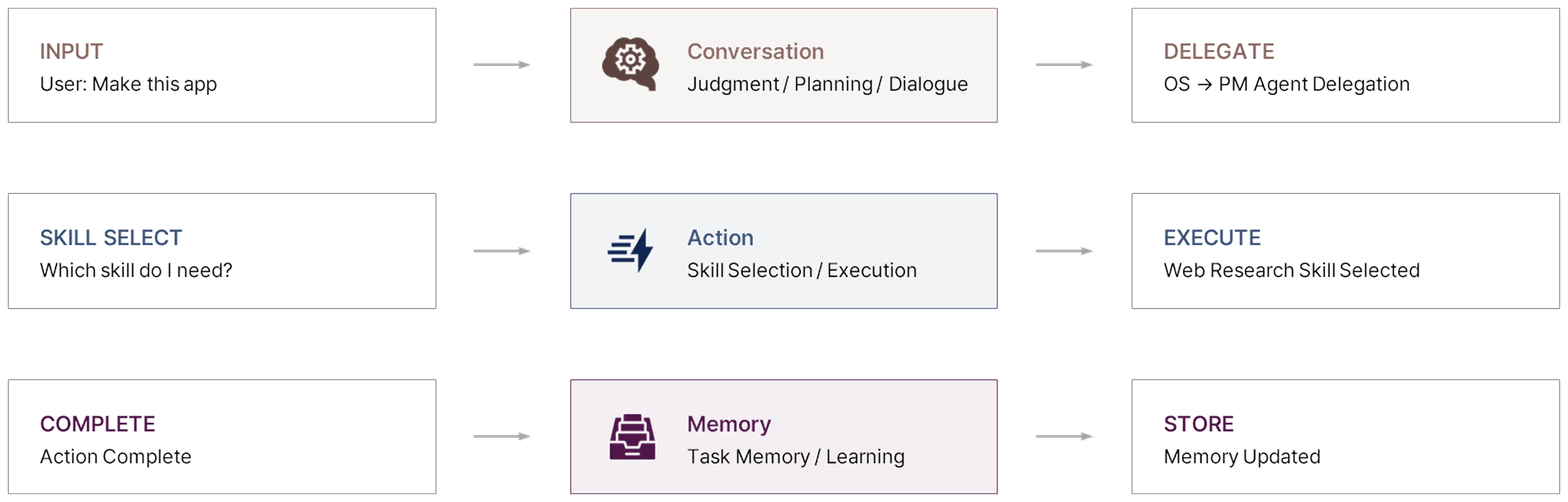
Conversation Brain은 사용자 또는 다른 에이전트와 자연어로 소통하며 대화를 만들고 다음 행동을 판단하는 역할을 합니다. Action Brain은 들어온 요청에 맞는 스킬, 도구, 함수를 선택하고 실행하는 역할입니다. Memory Brain은 작업 수행 결과를 요약하고 장기 기억으로 관리하며, 이후 추론에 활용될 수 있도록 맥락을 업데이트합니다.
각 에이전트는 이 Brain 타입을 필요에 따라 조합해 구성됩니다. OS Agent는 Conversation Brain을 중심으로 구성되어 사용자와의 대화와 서브 에이전트 위임을 담당합니다. 서브 에이전트는 Action Brain을 통해 자신이 가진 스킬을 실행하고, Memory Brain을 통해 결과를 장기 맥락에 반영합니다.
에이전트 하나가 추론, 행동, 기억을 모두 가진 독립적인 실행 단위가 됩니다. 스스로 판단하고, 실행하고, 기억합니다.
위임에서 실행까지, Brain 조합이 만드는 흐름
이 Brain 타입들이 실제로 어떻게 조합되어 시스템을 이루는지 살펴보겠습니다.
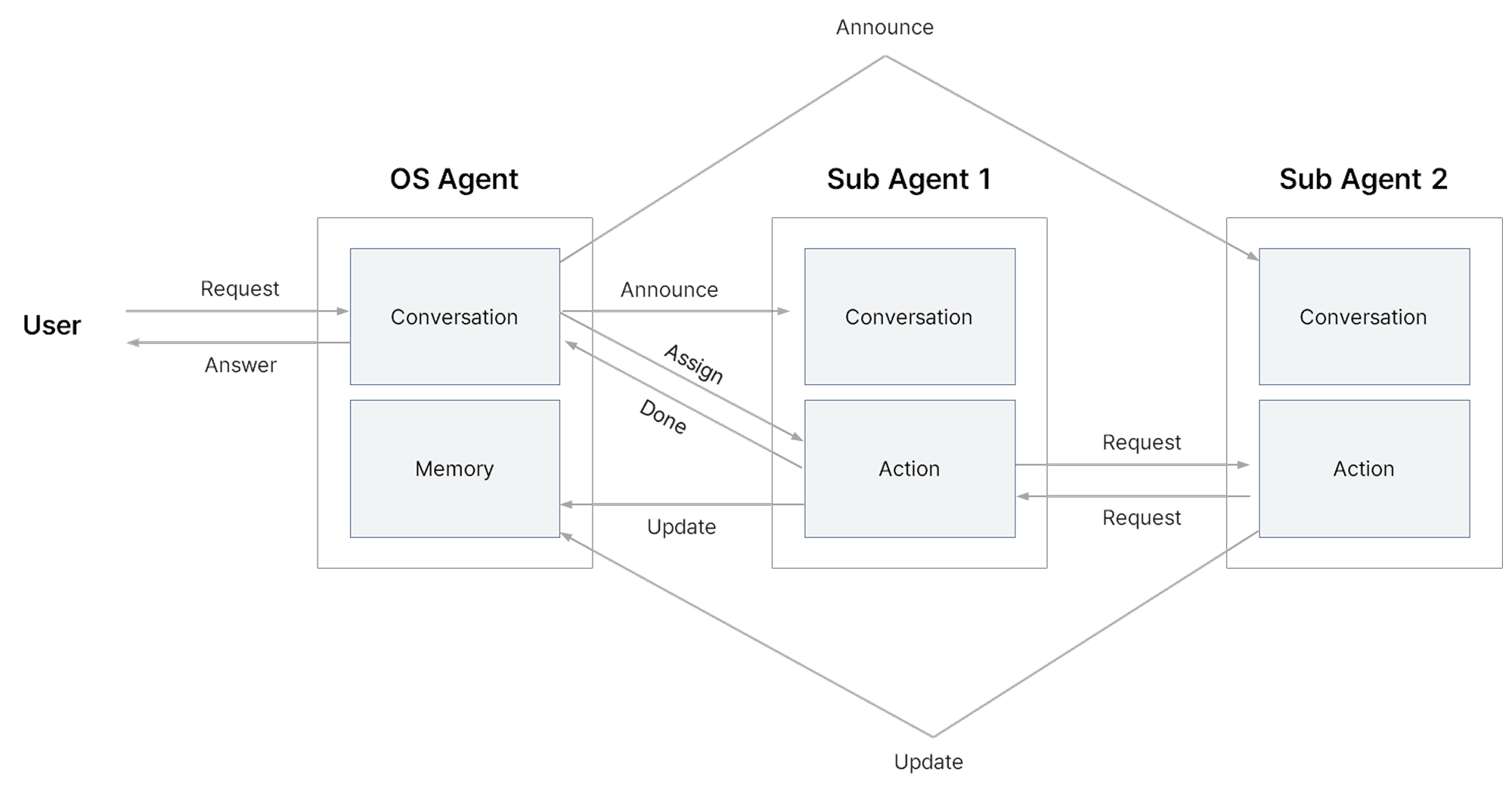
OS Agent는 Conversation Brain을 중심으로 작동하며, 사용자와의 대화를 담당하는 동시에 Sub Agent에게 작업을 위임하는 역할도 함께 맡습니다. Sub Agent에게 작업을 위임할 때는 해당 요청이 Sub Agent의 Action Brain으로 향하도록 합니다.
Sub Agent의 Action Brain은 자신이 가진 스킬, 도구, 함수 중 적합한 것을 선택해 작업을 수행합니다. 작업이 완료되면 결과를 OS Agent의 Conversation Brain으로 보고합니다. 경우에 따라 Sub Agent가 다른 Sub Agent에게 추가 요청을 보내야 할 때는, 해당 Sub Agent의 Action Brain으로 직접 요청이 전달됩니다.
작업 결과는 OS Agent의 Conversation Brain뿐 아니라 Memory Brain으로도 전달됩니다. 장기 기억을 업데이트하기 위해서입니다. 업데이트된 메모리는 이후 OS Agent가 답변을 생성할 때 활용됩니다.
특정한 경우에는 OS Agent의 Conversation Brain에서 Sub Agent의 Conversation Brain으로 Announce 기능이 작동됩니다. 이 Announce 기능에 대해서는 보다 더 자세히 살펴보겠습니다.
OS Agent는 어떻게 작업을 나누고 팀을 구성하는가
수신자가 명확한 작업은 Agent Calling으로 특정 에이전트에게 직접 위임합니다. Agent Calling 방식으로 에이전트에게 위임하면 OS Agent는 판단과 조율에만 집중하고 실제 실행은 각 에이전트가 분담합니다. 한 지점에서 오류가 발생해도 전체 흐름이 멈추지 않고, 에이전트가 스스로 후속 행동을 판단하며 작업을 이어갑니다. 시간이 갈수록 성능이 올라가는 자가 진화(self-evolving) 구조를 만들 수 있는 것도 이 방식 덕분입니다.
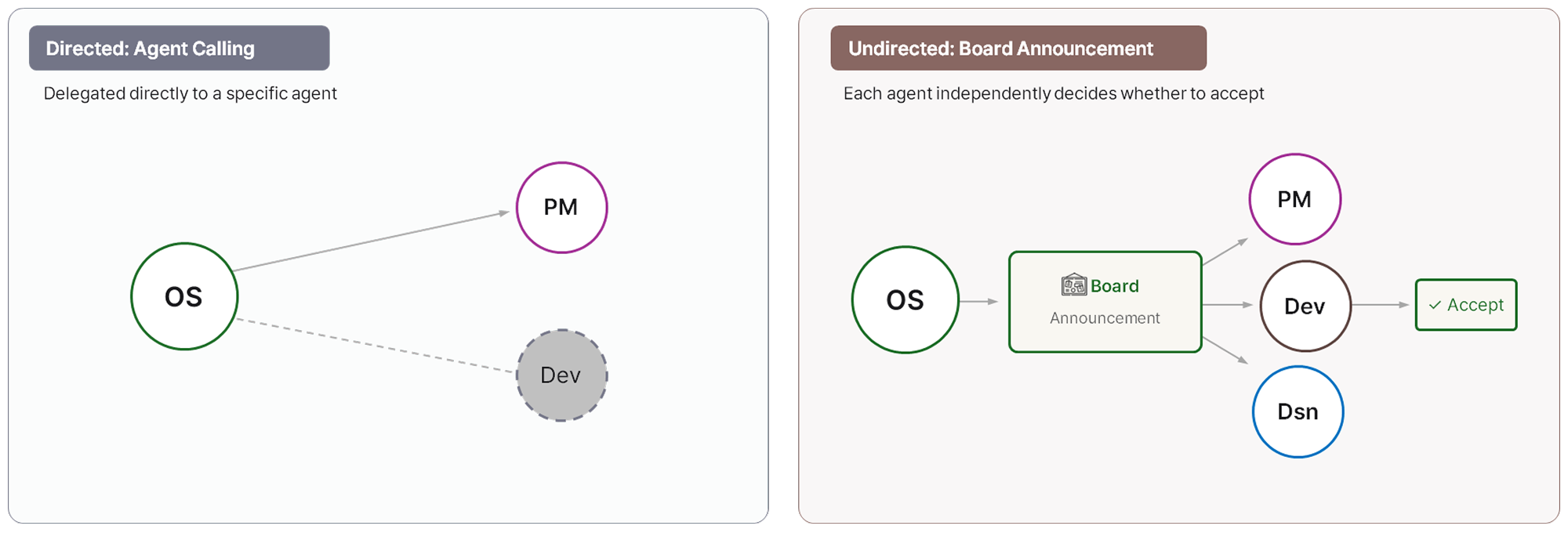
수신자가 불명확한 작업은 Board Announcement 방식으로 처리합니다. 작업을 모든 에이전트에게 동시에 전달(Board에 게시)하고, 각 에이전트가 자신이 처리할 수 있는지 스스로 판단해 가져가는 구조입니다. 담당자가 불명확한 상황에서도 작업이 중단되지 않고 완수되도록 하는 장치입니다.

또한, 이번 바둑 앱 시연에서는 바둑 교육 전문 에이전트가 그 자리에서 동적으로 생성됐습니다. Agent Spawning이라 부르는 이 구조는, 평소에 없던 에이전트를 특정 과업이 생겼을 때만 생성합니다. 별도의 배포 없이 기존 시스템 위에 플러그인처럼 추가되는 방식입니다. 시스템을 미리 크게 만들지 않아도, 필요한 전문성을 필요한 순간에 확보할 수 있습니다.
에이전트를 어떻게 연결하느냐, 그것이 작업의 범위를 결정합니다
"멀티 에이전트로 어떤 작업까지 가능한가"에 대한 답은 기능의 개수가 아닙니다.
에이전트들이 어떻게 통신하고, 어떻게 위임하고, 어떻게 실행하는지, 정확한 멀티 에이전트 프로토콜 설계가 가능한 작업의 범위를 결정합니다.
다음 2편에서는 이 시스템이 사용자와 어떻게 연결되고, 어떻게 보이는지, Bridge 레이어와 인터페이스 설계를 공개하겠습니다.
in solving your problems with Enhans!
We'll contact you shortly!