

저자: Wonduk Seo, Juhyeon Lee, Junseo Koh, Hyunjin An, Jian Park, Seunghyun Lee, Haihua Chen, Yi Bu
소속: AI Research, Enhans, Peking University, Fudan University, University of North Texas
사전 공개 버전: arXiv:2510.16635
논문 링크: https://arxiv.org/abs/2510.16635
요약
- 본 논문은 자동 프롬프트 최적화를 위한 점수 인식(score-aware) 멀티 에이전트 프레임워크인 MA-SAPO를 제안한다. MA-SAPO는 평가를 블랙박스 스칼라 값으로 취급하는 대신, 평가 점수를 해석 가능한 추론 산출물(reasoning artifacts)로 변환한다.
- MA-SAPO는 두 단계 구조를 가진다. 점수화된 프롬프트-응답 쌍으로부터 재사용 가능한 “추론 자산(reasoning assets)”을 구축하는 추론 단계(오프라인)와, 해당 자산을 검색·적용하여 근거 기반 프롬프트 수정을 수행하는 테스트 단계(온라인)로 구성된다.
- 핵심 아이디어는 메트릭을 구조화된 설명 및 진단과 결합하는 것이다. 에이전트는 각 메트릭 점수가 왜 발생했는지를 명시적으로 설명하고, 취약점과 트레이드오프를 식별한 뒤, 구체적인 수정 지침을 종합함으로써 최적화 과정을 투명하고 감사 가능하며 제어 가능하게 만든다.
- HelpSteer1/2 실험에서 MA-SAPO는 단일 패스 프롬프팅, RAG 기반 베이스라인, 기존 멀티 에이전트 시스템 대비 일관되게 다중 메트릭 품질을 개선하였다. 또한 테스트 시점에 2회의 호출만 사용하며, 토론/반복형 에이전트 프레임워크보다 훨씬 적은 출력 토큰을 사용한다.
초록
프롬프트 최적화는 대규모 언어 모델(LLM)을 재학습시키는 것에 대한 효율적인 대안이지만, 대부분의 기존 방법은 수치적 피드백만을 사용해 최적화하며, 프롬프트의 성공 또는 실패 원인에 대한 통찰을 제공하지 못하고 비용이 큰 시행착오에 의존한다. MA-SAPO는 다중 에이전트 파이프라인(설명, 진단, 종합)을 통해 메트릭 결과를 재사용 가능한 추론 자산으로 변환함으로써 이러한 한계를 해결한다. 테스트 시점에는 관련 자산을 검색하고 Analyzer–Refiner 워크플로우를 통해 근거 기반 수정을 적용한다. HelpSteer1/2 실험 결과, MA-SAPO는 도움성, 정확성, 일관성, 복잡성, 장황성 전반에서 일관된 성능 향상을 보였으며, 높은 효율성과 향상된 해석 가능성을 동시에 달성하였다.
서론
LLM의 성능은 프롬프트의 표현 방식과 구조에 매우 민감하므로, 프롬프트 최적화는 파인튜닝의 실용적인 대안이 된다. 기존 연구는 (i) 단일 패스 전략(CoT, 역할 프롬프팅, ToT/GoT 변형, 진화적 프롬프팅)과 (ii) 멀티 에이전트 프레임워크(토론, 비평 루프, 계층적 플래너)를 포함하지만, 공통적인 한계가 존재한다.
- 평가가 블랙박스인 경우가 많다. 대부분의 방법은 점수가 왜 높거나 낮은지 설명하지 않은 채 스칼라 점수만을 최적화한다.
- 수정이 시행착오 방식이다. 반복적인 재작성은 비용을 증가시키고 제어 가능성을 저하시킨다.
- 추론이 재사용되지 않는다. 모델이 추론을 수행하더라도, 그 통찰이 향후 수정에 활용 가능한 감사 가능한 자산으로 저장되지 않는다.
- 해석 가능성과 제어성이 제한적이다. 사용자는 장황성 대비 일관성과 같은 트레이드오프를 이해하거나 목표 지향적 조정을 적용하기 어렵다.
MA-SAPO는 프롬프트 최적화를 점수 인식 추론과 재사용 가능한 진단 지식의 검색 문제로 재정의한다.
데이터셋 및 평가 설정
데이터셋
MA-SAPO는 HelpSteer 계열 데이터셋에서 평가되며, 이는 프롬프트-응답 쌍과 함께 다섯 가지 인간 주석 품질 점수(0–4 스케일)를 제공한다.
- HelpSteer1: 약 35.3k 학습 / 약 0.79k 검증
- HelpSteer2: 약 20.3k 학습 / 약 1.04k 검증 (더 풍부한 주석, 약 29% 멀티턴, 선호 신호 포함)
HelpSteer2 학습 세트는 추론 자산 구성을 위한 검색 코퍼스로 사용된다.
평가 지표
다섯 가지 차원(각각 0–4, [0,1]로 정규화):
- 도움성(Helpfulness), 정확성(Correctness), 일관성(Coherence), 복잡성(Complexity), 장황성(Verbosity)
- 전체 점수 = 다섯 개 정규화 메트릭의 평균
모델
- 추론 자산 생성(오프라인): OpenAI o4-mini (자산 생성에만 사용)
- 테스트 시점 최적화 백본: GPT-4o, LLaMA-3-8B-Instruct (temperature=0)
- 판정자 / 평가자: ArmoRM-Llama3-8B-v0.1 보상 모델 (다섯 메트릭 점수 산출)
검색
- 희소 어휘 기반 검색: 프롬프트 텍스트에 대한 BM25
- 기본 top-k = 3 (어블레이션에서 최적 성능)
프레임워크: MA-SAPO (Framework: MA-SAPO)
핵심 아이디어: “점수가 개선될 때까지 다시 쓰기” 대신, MA-SAPO는 점수에 근거한 추론 메모리를 구축하고 이를 사용해 정당화된 목표 지향 수정을 적용한다.
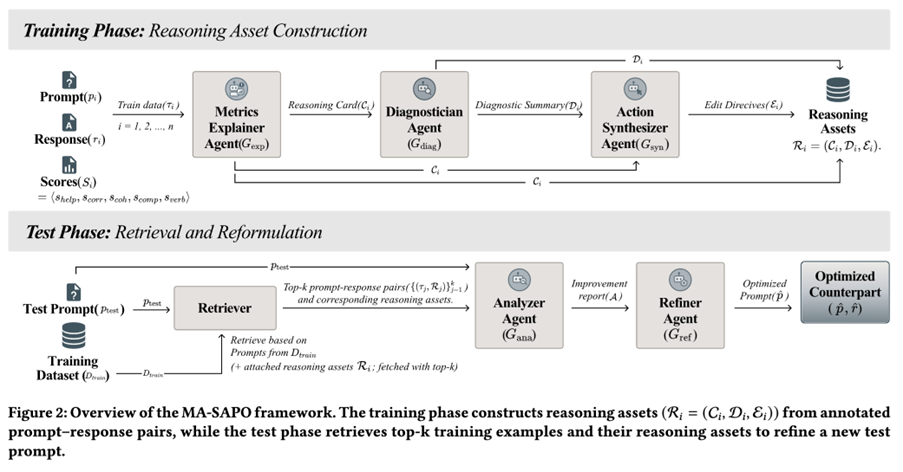
MA-SAPO는 두 단계로 구성된다.
1) 추론 단계 (학습 / 오프라인): 추론 자산 구성
각 학습 인스턴스는 삼중항으로 정의된다:
τᵢ = (프롬프트 pᵢ, 응답 rᵢ, 점수 Sᵢ)
세 개의 에이전트가 순차적으로 실행되어 재사용 가능한 자산 Rᵢ = (Cᵢ, Dᵢ, Eᵢ)를 생성한다.
(a) 메트릭 설명 에이전트(Metric Explainer Agent, G_exp)
각 메트릭 점수가 왜 부여되었는지와 이를 개선하기 위한 요소를 설명하는 추론 카드 Cᵢ를 생성한다.
(b) 진단 에이전트(Diagnostician Agent, G_diag)
취약한 메트릭의 근본 원인과 메트릭 간 트레이드오프(예: 세부 설명 추가는 장황성을 높이지만 일관성을 낮출 수 있음)를 식별하는 진단 요약 Dᵢ를 생성한다.
(c) 행동 종합 에이전트(Action Synthesizer Agent, G_syn)
설명과 진단을 구체적인 수정 지침 Eᵢ(“무엇을 바꿔야 하는지”에 대한 명확한 가이드)로 변환한다.
이러한 자산은 반구조화 텍스트로 저장되며, 테스트 시점 최적화를 위한 검색 코퍼스로 활용된다.
2) 테스트 단계 (온라인): 검색 + 근거 기반 최적화
새로운 프롬프트 p_test가 주어지면,
(a) 추론 자산을 포함한 유사 학습 예시 상위 k개를 검색한다: {(τⱼ, Rⱼ)}, j=1..k
(b) 분석 에이전트(Analyzer Agent, G_ana)
p_test를 검색된 예시 및 자산과 비교하여 개선 보고서를 생성한다.
– 불명확하거나 과소 명시된 부분
– 누락된 구조
– 피해야 할 트레이드오프
– 검색된 근거에 의해 뒷받침되는 수정 사항
(c) 정제 에이전트(Refiner Agent, G_ref)
Analyzer 보고서를 바탕으로, 임의적 재작성이 아닌 근거 기반 지침을 우선하여 최적화된 프롬프트 p̂를 생성한다.
최종적으로 p̂를 사용해 최적화된 응답 r̂를 생성하고, 판정 모델이 (p̂, r̂)를 평가한다.
비교 기준 방법 (Baselines)
총 여섯 개의 베이스라인을 범주별로 비교한다.
단일 패스(검색 없음)
- Direct Generation
- Chain-of-Thought (CoT)
- Role Assignment
검색 증강(추론 자산 없음)
- RAG (BM25 기반 예시 검색, k=10)
멀티 에이전트 프레임워크
- MAD (Multi-Agent Debate)
- MARS (Planner + Teacher/Critic/Student, 반복 구조)
실험 결과
주요 결과
HelpSteer1과 HelpSteer2 전반에서 MA-SAPO는 두 백본 모두에서 다섯 개 메트릭 평균 점수 기준 최고 성능을 달성하였다.
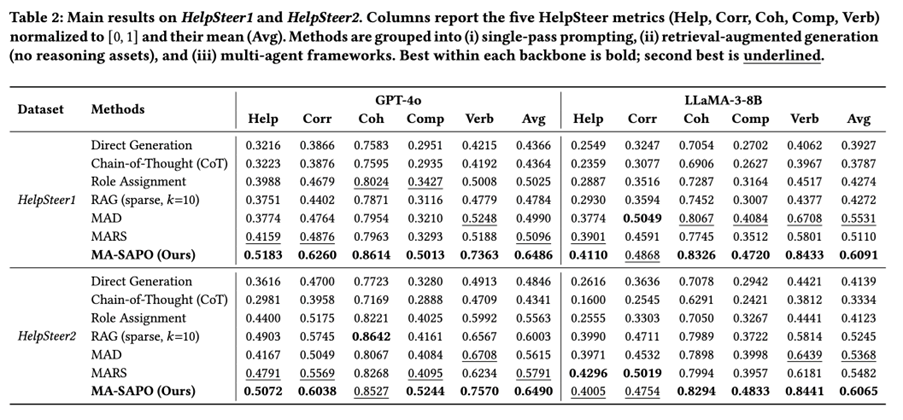
- HelpSteer1 (GPT-4o): MA-SAPO 0.6486 Avg, MARS 0.5096, RAG 0.4784
- HelpSteer2 (GPT-4o): MA-SAPO 0.6490 Avg, RAG 0.6003, MARS 0.5791
- HelpSteer1 (LLaMA-3-8B): MA-SAPO 0.6091 Avg, MAD 0.5531, MARS 0.5110
- HelpSteer2 (LLaMA-3-8B): MA-SAPO 0.6065 Avg, MARS 0.5482, RAG 0.524
해석: MA-SAPO의 성능 향상은 (i) 검색과 (ii) 왜 수정이 필요한지를 설명하는 점수 기반 추론 자산의 결합에서 기인한다.
구성 요소별 성능 분석 (Ablation Studies)
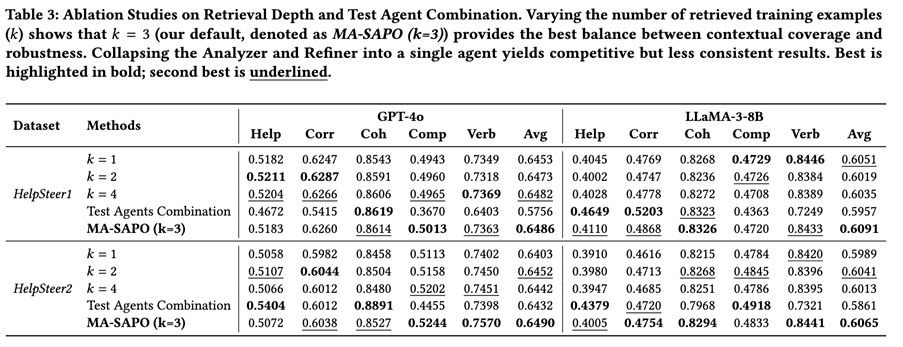
(1) 검색 깊이 k
결과: k=3이 가장 일관되게 우수한 설정이다. 작은 k는 다양성이 부족하고, 큰 k는 노이즈와 상충 신호를 증가시킨다.
(2) Analyzer와 Refiner를 단일 에이전트로 통합
일부 메트릭에서는 경쟁력 있으나 전반적 일관성은 낮다. 결론적으로 진단(Analyzer)과 실행(Refiner)을 분리하는 것이 신뢰성과 감사 가능성을 향상시킨다.
정성적 분석
주석자: 전문가 14명(데이터 사이언티스트 / AI 엔지니어 / 대학원생)
가설 H1: 추론 품질(30 사례)
MA-SAPO 멀티 에이전트 추론과 단일 에이전트 베이스라인을 다음 기준으로 비교하였다.
- 유용성, 정확성, 일관성 (1–5 Likert 척도)
MA-SAPO는 세 항목 모두에서 개선을 보였으며, 유용성과 정확성은 통계적으로 유의미한 향상을 나타냈다.
가설 H2: 방향 일관성(40 프롬프트 쌍)
최적화된 프롬프트가 원래 의도를 얼마나 유지하는지를 측정하였다(1–4 스케일).
결과: 평균 3.36 / 4로, 대부분 3–4에 분포했으며, 수정은 의도를 벗어나기보다는 구조와 명확성을 개선하는 경향을 보였다.
결론
MA-SAPO는 평가 신호를 검색 가능하고 해석 가능한 추론 자산으로 변환하고, 멀티 에이전트 분석을 통해 근거 기반 수정을 적용함으로써 자동 프롬프트 최적화에 대한 실용적인 접근법을 제시한다. 본 방법은 HelpSteer1/2와 두 가지 백본 모델 전반에서 성능을 향상시키면서도, 테스트 시점 비용을 낮게 유지하고 의미적 의도를 보존한다.
in solving your problems with Enhans!
We'll contact you shortly!