

저자: Wonduk Seo, Juhyeon Lee, Hyunjin An, Seunghyun Lee, Yi Bu
소속: 인핸스(Enhans), 베이징대학교(Peking University)
게재: 25th ACM/IEEE Joint Conference on Digital Libraries (JCDL)
논문: Better by Comparison: Retrieval-Augmented Contrastive Reasoning for Automatic Prompt Optimization
TL;DR
- 본 논문은 프롬프트를 개별적으로 최적화하는 기존 방식과 달리, 고품질 및 저품질 프롬프트–응답 예시를 명시적으로 비교함으로써 프롬프트 품질을 개선하는 검색 증강 기반 프레임워크인 CRPO(Contrastive Reasoning Prompt Optimization)를 제안한다.
- CRPO는 프롬프트 최적화를 하나의 단일 최적화 문제가 아니라, 대조적 추론(contrastive reasoning) 문제로 재정의하며, LLM이 여러 인간 중심 품질 지표가 주석된 검색 예제를 바탕으로 어떤 프롬프트가 성공하거나 실패하는지를 성찰하도록 유도한다.
- 이 프레임워크는 두 가지 상호 보완적인 전략을 제안한다. 첫째, 고·중·저 품질 프롬프트–응답 쌍을 대비시키는 계층적 대조 추론(Tiered Contrastive Reasoning), 둘째, 유용성, 정확성, 응집성, 복잡도, 장황성 등 여러 평가 지표별 최적 예시를 통합하는 다중 지표 대조 추론(Multi-Metric Contrastive Reasoning)이다.
- HelpSteer2 벤치마크에서 수행한 실험 결과, CRPO는 GPT-4o와 LLaMA-3-8B 모두에서 Direct Generation, Chain-of-Thought 프롬프팅, 표준 RAG 방식보다 일관되게 우수한 성능을 보였다.
- CRPO는 모델 파인튜닝 없이 프롬프트 품질을 향상시키며, 실제 LLM 응용 환경에서 적용 가능한 실용적이고 해석 가능하며 확장 가능한 자동 프롬프트 최적화 해법을 제공한다.
초록
대규모 언어 모델의 신뢰성과 유용성을 향상시키기 위해 자동 프롬프트 최적화는 점점 더 중요한 요소가 되고 있다. 그러나 기존 접근법의 대부분은 직접적인 반복 개선이나 점수 기반 최적화에 의존하며, 더 나은 예시와 더 나쁜 예시 사이에 존재하는 풍부한 비교 신호를 충분히 활용하지 못하고 있다. 이러한 한계를 해결하기 위해, 본 논문은 프롬프트–응답 쌍에 대한 대조적 추론을 명시적으로 활용하는 검색 증강 프레임워크인 CRPO를 제안한다. CRPO는 HelpSteer2 데이터셋에서 주석된 예제를 검색하여, 어떤 프롬프트가 우수한 응답을 생성하는지, 그리고 어떤 프롬프트가 실패하는지를 LLM이 직접 성찰하도록 한다. 계층적 대조 추론과 다중 지표 대조 추론이라는 두 가지 전략을 통해, CRPO는 여러 평가 차원에서의 강점을 통합한 최적화된 프롬프트를 생성한다. 실험 결과는 CRPO가 강력한 기존 기준 방법들을 크게 능가함을 보여주며, 대조적이고 검색 기반의 추론이 프롬프트 최적화에 효과적임을 입증한다.
서론
프롬프트의 품질은 대규모 언어 모델의 성능을 결정짓는 핵심 요소이다. 문구의 사소한 차이만으로도 응답의 정확성, 유용성, 응집성에서 큰 차이가 발생할 수 있다. 최근에는 소프트 프롬프트 튜닝, 진화적 탐색, 에이전트 기반 탐색 등 다양한 자동 프롬프트 최적화 기법이 연구되어 왔지만, 이들 대부분은 하나의 공통된 한계를 지닌다. 즉, 좋은 예시와 나쁜 예시를 명시적으로 비교하며 학습하지 않는다는 점이다.
실제 인간은 프롬프트를 개선할 때 대비를 통해 학습한다. 어떤 프롬프트가 더 나은 결과를 만들어내는지, 그리고 그 이유가 무엇인지를 비교하면서 이해한다. 그러나 기존의 자동화된 방법들은 이러한 비교적 추론을 거의 반영하지 못하고 있다. 또한 많은 프레임워크가 수작업으로 설계된 파이프라인에 의존하거나, 정답 정확도에만 초점을 맞추어 해석 가능성이나 사용성과 같은 인간 중심의 요소를 간과한다.
CRPO는 이러한 관점에서 출발한다. 프롬프트 최적화를 단일 경로의 점진적 개선 문제로 취급하는 대신, 검색된 예제를 기반으로 한 대조적 추론 과제로 재정의한다. 프롬프트와 그에 따른 응답을 여러 품질 차원에서 비교함으로써, CRPO는 실패 패턴과 성공 요인을 명시적으로 추론하게 하고, 그 결과 더 견고하고 해석 가능한 프롬프트 최적화를 가능하게 한다.
데이터셋 및 평가 설정
데이터셋
CRPO는 프롬프트 최적화와 응답 품질 분석을 위해 설계된 대규모 벤치마크인 HelpSteer2 데이터셋에서 평가된다. 이 데이터셋은 2만 개 이상의 학습 예제와 별도의 검증 세트로 구성되어 있으며, 각 프롬프트–응답 쌍은 다음 다섯 가지 차원에서 인간 평가자의 주석을 포함한다.
- 유용성: 응답이 프롬프트를 얼마나 잘 충족하는지
- 정확성: 사실적 정확성과 오류의 부재
- 응집성: 명확성과 논리적 일관성
- 복잡도: 응답이 보여주는 깊이와 전문성 수준
- 장황성: 응답 길이의 적절성
이러한 세분화된 주석 구조는 HelpSteer2를 대조적 추론에 특히 적합한 데이터셋으로 만든다.

모델 및 평가 방식
실험에는 GPT-4o와 LLaMA-3-8B가 사용되었다. 검색 단계에서는 프롬프트 텍스트를 기반으로 한 희소 검색을 통해 상위 k개의 참조 예제를 추출한다. 평가는 다중 목표 보상 모델을 활용하여 다섯 가지 차원에서 생성된 응답을 점수화하고, 이를 정규화한 뒤 평균 점수로 비교한다. 전체 프레임워크는 CRPO를 기반으로 구성된다.
CRPO 프레임워크
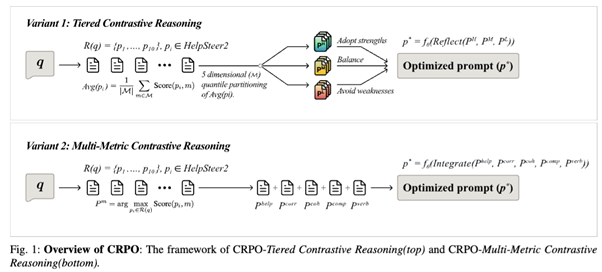
CRPO의 핵심 아이디어는 더 나은 프롬프트를 만들기 위해, 더 좋은 사례와 더 나쁜 사례의 차이를 명시적으로 추론한다는 것이다. CRPO는 참조 예제 검색 단계와 대조적 추론 기반 프롬프트 합성 단계의 두 단계로 구성된다.
1. 참조 프롬프트–응답 쌍 검색
입력 쿼리가 주어지면, CRPO는 HelpSteer2 학습 세트에서 관련 있는 프롬프트–응답 쌍을 검색한다. 이때 프롬프트 텍스트뿐 아니라 생성된 응답도 함께 활용하여, 프롬프트의 표현 방식이 출력 품질에 어떤 영향을 미치는지를 여러 차원에서 추론할 수 있도록 한다.
2. 대조적 추론 전략
CRPO는 두 가지 상호 보완적인 최적화 변형을 제안한다.
(a) 계층적 대조 추론
검색된 예제들을 전체 품질 점수에 따라 고·중·저 품질 그룹으로 나눈다. 모델은 저품질 예제에서 나타나는 약점을 피하고, 고품질 예제의 강점을 채택하며, 중간 품질 예제를 안정적인 기준점으로 활용하도록 유도된다. 이 구조는 극단적인 사례에 과도하게 치우치는 것을 방지하면서도 일관된 개선을 가능하게 한다.
(b) 다중 지표 대조 추론
이 방식은 전체 품질 점수 대신, 각 평가 차원별로 가장 우수한 예제를 선택한다. 이후 유용성, 정확성, 응집성, 복잡도, 장황성 측면에서 각각의 강점을 하나의 최적화된 프롬프트로 통합한다.
실험 결과
주요 결과
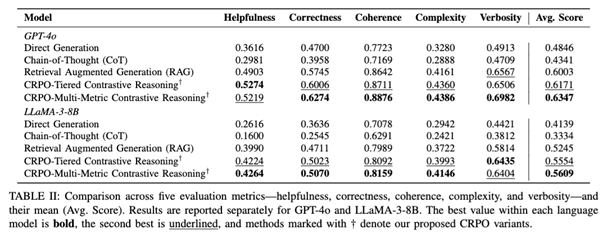
GPT-4o와 LLaMA-3-8B 모두에서 CRPO는 다음 방법들을 일관되게 능가한다. 외부 근거를 사용하지 않는 Direct Generation, 장황성만 증가시키고 사실적 품질은 개선하지 못하는 Chain-of-Thought 프롬프팅, 그리고 예제를 검색하지만 대비 추론을 수행하지 않는 표준 RAG 방식이다. 두 가지 CRPO 변형 모두 다섯 가지 평가 차원 전반에서 더 높은 평균 점수를 달성했으며, 특히 다중 지표 대조 추론이 전반적으로 가장 우수한 성능을 보였다.
제거 실험(Ablation)
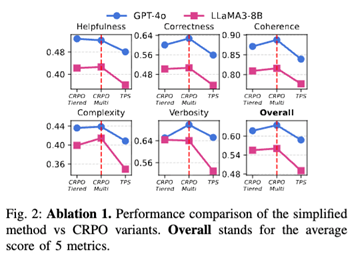
검색만 사용하고 대조적 추론을 제거한 경우, 성능이 뚜렷하게 저하되었다. 이는 CRPO의 성능 향상이 단순한 검색 효과가 아니라, 비교 기반 추론에서 비롯된 것임을 보여준다.
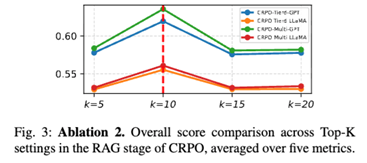
또한 검색 예제 수가 적절할 때 성능이 향상되지만, 지나치게 많은 예제를 포함하면 추론의 명확성이 떨어져 성능이 감소하는 경향이 나타났다.
결론
CRPO는 프롬프트 최적화가 단순한 개선이 아니라 비교를 통해 이루어진다는 점을 실증적으로 보여준다. 고품질과 저품질 프롬프트–응답 쌍을 명시적으로 대비하고, 여러 인간 중심 평가 지표에 걸친 통찰을 통합함으로써, CRPO는 더 견고하고 해석 가능하며 사용자 의도에 부합하는 프롬프트를 생성한다. 모델 파인튜닝이나 경직된 최적화 파이프라인에 의존하지 않고, 전적으로 추론 시점에서 동작하기 때문에 기존 LLM 워크플로우에 쉽게 통합될 수 있다. 이러한 특성으로 인해 CRPO는 대화형 에이전트부터 의사결정 지원 시스템에 이르기까지 다양한 실제 응용 환경에서 활용 가능한 실용적이고 확장성 있는 프레임워크이다.
in solving your problems with Enhans!
We'll contact you shortly!