
.png)
저자: Wonduk Seo, Daye Kang, Hyunjin An, Taehan Kim, Soohyuk Cho, Seungyong Lee, Minhyeong Yu, Jian Park, Yi Bu, Seunghyun Lee
소속: Enhans, Kaist, UC Berkeley, Princeton University, Fudan University, Peking University
게재: International Conference on Pattern Recognition (ICPR)
요약
- 본 논문은 VisPath라는 프레임워크를 제안한다. VisPath는 텍스트 입력으로부터 시각화 코드를 생성하는 문제를, 단일 프롬프트에서 바로 코드를 뽑는 단일 경로 방식이 아니라, 다양한 후보 추론 경로를 탐색하고 시각적 평가를 거쳐 최종 코드를 선택하는 검색 문제로 재구성한다.
- VisPath는 세 단계로 동작한다. (i) Multi-Path Agent가 사용자 질의와 데이터셋 설명으로부터 서로 다른 다수의 추론 경로를 생성하고, (ii) Code Generation Agent가 각 경로를 실행 가능한 시각화 코드로 변환하며, (iii) Feedback 및 통합 단계에서 비전-언어 모델(VLM)이 렌더된 플롯을 평가하고 최종 최적화된 스크립트를 합성한다.
- MatPlotBench와 Qwen-Agent Code Interpreter Visualization 벤치마크에서, VisPath는 Zero-Shot prompting, CoT prompting, Chat2VIS, MatPlotAgent와 같은 강력한 기준선 대비 일관되게 더 나은 성능을 보였다. 특히 GPT-4o mini와 Gemini 2.0 Flash 환경에서 Plot Score 최대 9.14점 향상, Executable Rate 최대 10%포인트 향상을 달성한다.
- Ablation 및 비용 분석 결과, 소수의 추론 경로(K = 3)와 구조화된 시각 피드백 조합이 품질과 효율성 간의 최적 균형을 제공함을 보였다.
- VisPath는 비즈니스 대시보드, 분석 리포트, 최적화 모니터링 등에서, 모호하거나 정보가 불완전한 자연어 질의까지 처리 가능한 견고하고 설명 가능하며 실서비스에 적합한 시각화 코드 자동 생성 경로를 제시한다.
초록
대규모 언어 모델(LLM)은 자연어 지시만으로 차트를 생성할 수 있게 해주는 자동 시각화 코드 생성의 핵심 기술로 자리 잡았다. Few-shot prompting이나 쿼리 확장(query expansion) 같은 기법이 도입되면서 성능은 개선되었지만, 기존 방법들은 모호하거나 복잡한 질의를 효과적으로 처리하지 못하는 경우가 여전히 많고, 그 결과 사용자의 수동 개입이 자주 필요하다는 한계가 있다.
이 한계를 극복하기 위해, 본 논문은 시각화 코드 생성을 위한 Multi-Path Reasoning 및 Feedback-Driven Optimization Framework인 VisPath를 제안한다. VisPath는 정보가 충분히 주어지지 않은(underspecified) 질의를 구조화된 다단계 처리 파이프라인으로 다룬다.
먼저 Chain-of-Thought(CoT) 프롬프트를 활용해 사용자의 초기 입력을 재구성하고, 이를 여러 개의 확장된 질의로 병렬 생성하여 사용자 의도에 대한 다양한 해석을 포착한다. 이후 각 질의는 후보 시각화 스크립트를 생성하는 데 사용되며, 이 스크립트들은 실행을 거쳐 서로 다른 시각적 결과 이미지를 만든다. VisPath는 각 결과물의 시각적 품질과 정합성을 평가하여, 그에 기반한 타깃 피드백을 생성하고, 이 피드백들을 통합해 최종 최적 해를 합성한다.
MatPlotBench 및 Qwen-Agent Code Interpreter Benchmark를 포함한 널리 사용되는 벤치마크에서의 광범위한 실험을 통해, VisPath가 최신 기법들을 능가하며, AI 기반 시각화 코드 생성의 신뢰성을 크게 향상시키는 방법임을 보인다.
서론
시각화는 필수적이지만, 시각화 코드를 작성하는 일은 그렇지 않다. 분석가, 연구자, 비즈니스 실무자는 패턴 탐색, KPI 모니터링, 모델 행태 설명을 위해 플롯이 필요하지만, “무엇을 보고 싶은지”라는 요구로부터 정확한 Matplotlib 혹은 Seaborn 코드로 이어지는 과정은 여전히 많은 인력과 시간이 필요하다.
LLM 기반 시스템은 “자연어로 요청하면 바로 실행 가능한 코드가 나온다”는 약속을 통해 이 과정을 단축해줄 것으로 기대된다. 그러나 현재 대부분의 접근법은 단일 추론 경로(single reasoning trajectory)에 의존한다. 하나의 질의를 하나의 코드 스니펫으로 매핑하며, 경우에 따라 CoT 프롬프트나 템플릿을 사용하기도 하지만, 대안적인 해석을 체계적으로 탐색하지는 않는다.
이러한 구조는 실제 현장에서 자주 등장하는 상황에서 쉽게 무너진다. 예를 들어:
- 모호한 지시
- “핵심 지표들의 시간 경향을 보여줘”
- 시각적 설계 선택이 충분히 명시되지 않은 경우
- 축, 집계 단위, 여러 시리즈를 어떻게 조합할지
- 복합적인 요구
- “이 데이터를 세 가지 다른 방식으로 시각화해줘”
템플릿 기반 시스템(예: prefix-guided 방식)은 제어하기 쉽지만 유연성이 떨어진다. 반복적인 self-debug 구조는 문법 오류나 런타임 에러를 고칠 수는 있지만, 여전히 동일한 의미 구조(semantic path) 안에서만 움직이기 때문에, 처음 해석이 틀리면 이후의 수정도 모두 그 오해 위에서 이뤄진다. 결과적으로 코드는 실행되지만 의미적으로 빗나간 플롯이 자주 나오고, 이는 사용자의 수동 수정 작업을 유발해 자동화의 목적을 약화시킨다.
VisPath는 이에 대해 다른 관점을 제시한다.
“하나의 해석에 너무 일찍 고정되지 말자.”
시각화 생성 과정을 다음과 같이 본다.
- 가능한 여러 추론 경로를 탐색한다.
- 각 경로를 후보 코드 및 시각적 결과물로 변환한다.
- 시각적 피드백을 활용해 최종 답안을 통합한다.
즉, 시각화 코드 생성 전체를 다중 경로 탐색과 시각 피드백 기반 통합 과정으로 재정의한다.
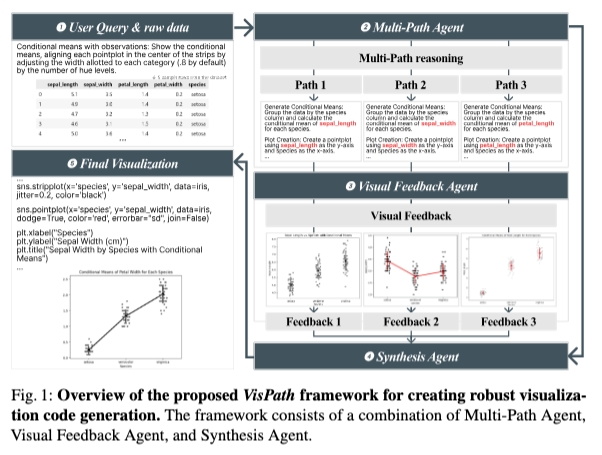
데이터셋 및 방법
데이터셋
VisPath는 두 개의 텍스트 기반 시각화 벤치마크에서 평가된다.
- MatPlotBench
- 약 100개의 항목과 각 항목에 대응하는 정답 이미지가 존재한다.
- 상대적으로 단순한 지시문에 초점을 맞추지만, 세부적인 스타일링, 레이아웃, 집계와 같은 미묘한 시각화 과제를 포함한다.
- 생성된 코드의 정답 이미지와의 유사도 및 실행 가능성(executability)으로 평가된다.
- Qwen-Agent Code Interpreter Benchmark (Visualization subset)
- 총 295개 중 163개가 시각화 관련 예제이다.
- 수학, 데이터 시각화, 파일 작업 등의 과제를 포함한다.
- 시각화 과제는 코드의 정합성과 실행 결과를 바탕으로 Visual-Hard, Visual-Easy, Average 지표로 평가된다.
두 데이터셋은 함께 사용될 때,
- MatPlotBench는 이미지 유사도 및 미적 타당성을,
- Qwen 벤치마크는 코드 인터프리터 환경에서의 실행 가능성과 논리적 정확성을 강조한다.
모델 및 평가 설정
코드 생성 및 추론용 LLM
사용된 코드 추론 모델은 다음과 같다.
- GPT-4o mini
- Gemini 2.0 Flash
이 모델들은 다음 역할을 수행한다.
- 사용자 질의를 여러 개의 추론 경로로 확장
- 각 추론 경로를 기반으로 시각화 코드를 생성
출력의 안정성과 집중도를 위해, 기존 연구를 따라 temperature는 0.2로 설정하였다.
피드백용 비전-언어 모델
- GPT-4o와 일부 설정에서는 Gemini 2.0 Flash를 시각 평가 모델로 사용한다.
- VLM은 렌더링된 플롯 이미지 또는 에러 메시지와 코드를 함께 입력받아 평가를 수행한다.
- 피드백은 다음 항목을 포함하는 구조화된 형태로 생성된다.
- 질의와의 정합성
- 플롯 레이아웃과 가독성
- 데이터와 시각 표현 간의 매핑 정확도
- 개선을 위한 구체적인 제안
평가지표
- MatPlotBench
- Plot Score (0–100): 생성된 플롯이 기준 플롯과 얼마나 유사한지 나타내는 점수
- Executable Rate (%): 에러 없이 실행되는 코드 스니펫의 비율
- Qwen-Agent Visualization
- Visualization-Hard, Visualization-Easy, Average
- 예상 결과와의 일치 여부 및 실행 결과를 기반으로 산출되는 코드 정확도 지표
비교 기준선
공정한 비교를 위해, 모든 기준선은 동일한 LLM 백본 위에서 평가된다.
- Zero-Shot
- 사용자 질의로부터 직접 시각화 코드를 생성하는 가장 기본적인 방식
- CoT Prompting
- 단일 Chain-of-Thought 추론 후 코드 생성
- Chat2VIS
- prefix 기반 가이드 템플릿을 활용하여 코드 생성을 구조화하고, 모호성을 완화하려는 접근
- MatPlotAgent
- VLM 피드백을 사용해 쿼리 확장과 iterative self-debug를 수행하는 에이전트
- 비교의 공정성을 위해 최대 세 번의 반복으로 제한
VisPath 설정
- 기본 설정에서 K = 3개의 추론 경로를 사용한다.
- 각 경로마다
- 하나의 후보 시각화 스크립트
- 한 번의 시각 피드백 라운드가 생성된다.
- 모든 에이전트의 프롬프트는 표준화되어 있으며, 상세 내용은 부록에 제시된다 (본 게시글에서는 생략).
프레임워크: VisPath

VisPath의 핵심 아이디어는 다음 한 문장으로 요약된다.
“여러 해석을 탐색하고, 각 해석에서 코드를 생성한 뒤, 시각 피드백을 이용해 하나의 최종 스크립트로 통합한다.”
VisPath는 세 단계 파이프라인으로 구현된다.
1. 다중 경로 질의 확장
입력은 사용자 질의 Q와 데이터셋 설명 D이다.
Multi-Path Agent(LLM)는 K개의 상이한 추론 경로 RiR_iRi를 생성한다.
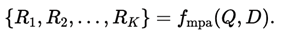
각 RiR_iRi는 다음을 명시하는 구조화된 설계 청사진(blueprint)이다.
- 어느 변수를 플롯할지
- 어떤 방식으로 집계할지
- 차트 타입과 레이아웃
- 색 인코딩, 그룹핑 등 주요 설계 결정
이때 목표는 단순히 많은 수의 경로를 만드는 것이 아니라, 서로 실제로 다른, 그럴듯한 해석들을 소수 생성하는 것이다. 모든 추론 경로는 데이터셋 설명 D에 기반해, 실제 존재하는 컬럼과 의미 구조에 정합되도록 제약된다.
2. 코드 생성 및 실행
각 추론 경로 Ri에 대해, Code Generation LLM은 Python 시각화 스크립트 Ci를 생성한다.
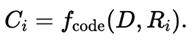
생성된 스크립트는 실행되어 다음 중 하나의 결과를 낳는다.
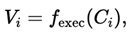
- 플롯 이미지 생성
- 런타임 에러 발생
실행 가능성은 이진 변수 ϵi로 기록된다.
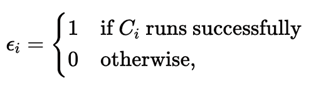
- ϵi = 1: 실행 성공
- ϵi = 0: 실행 실패
이에 따라, 라우팅된 출력 ZiZ_iZi는 다음과 같이 정의된다.
- ϵi=1\epsilon_i = 1ϵi=1일 때: 플롯 이미지
- ϵi=0\epsilon_i = 0ϵi=0일 때: 에러 메시지와 관련 컨텍스트
이 단계의 결과는 후보 삼중항 (Ci,Zi,ϵi)들의 집합이다.
3. 피드백 기반 통합
Feedback Model(VLM)은 각 후보에 대해 다음 함수를 수행한다.
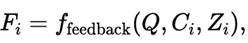
- 입력: Ci, Zi, 원래 질의 Q, 데이터 설명 D
- 출력: 의미적, 시각적 품질에 대한 구조화된 피드백
각 후보는 다음과 같은 요약 형태로 정리된다.
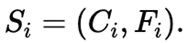
- 질의와의 정합성 평가
- 시각적 구성과 가독성 평가
- 데이터와 시각 표현 간의 매핑 정확성
- 향후 개선을 위한 명시적 제안
Integration Module은 이 요약과 피드백을 기반으로, 후보들 전반에서 발견된 장점을 결합하고 피드백에서 지적된 약점을 수정하여 최종 코드 C*를 합성한다.
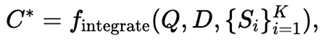
이로써 C*는
- 원래 사용자 질의에 의미적으로 잘 맞고
- 실제 실행 가능한
- 시각적으로도 견고한 시각화 스크립트가 된다.
실험 결과
주요 결과
VisPath는 GPT-4o mini와 Gemini 2.0 Flash를 백본으로 사용한 환경에서, MatPlotBench와 Qwen-Agent Visualization 벤치마크 상에서 Zero-Shot, CoT Prompting, Chat2VIS, MatPlotAgent와 비교된다.
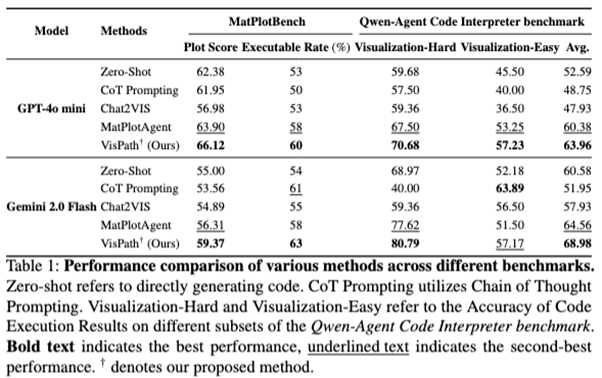
전체 실험 설정 전반에서, VisPath는 다음과 같은 성과를 보인다.
- Plot Score 기준 최대 9.14점 향상
- Executable Rate 기준 최대 10%포인트 향상
특히 polar plot, 다중 subplot 레이아웃, 복합적(compositional) 시각화처럼 난도가 높은 사례에서 MatPlotAgent를 포함한 모든 기준선보다 일관되게 우수한 성능을 달성한다.
결론
VisPath는 시각화 코드 생성 문제를, 기존의 단일 프롬프트에서 코드로 직접 매핑하는 방식이 아니라, 다중 경로 추론과 피드백 통합 문제로 재정의한다.
VisPath는 다음 세 가지 과정을 통해 이를 실현한다.
- 동일한 사용자 질의와 데이터셋으로부터 다양한 추론 경로를 생성하고
- 각 경로를 실행 가능한 시각화 코드로 변환하며
- 렌더링된 결과에 대한 시각 피드백을 활용해 최종 스크립트를 합성한다.
이 구조를 통해 VisPath는 기존 LLM 기반 기법 대비
- 더 높은 플롯 품질,
- 더 나은 실행 가능성,
- 모호한 질의에 대한 높은 견고성을 보여준다.
비즈니스 분석, 리포팅, 최적화 파이프라인과 같은 환경에서, VisPath는
- 모호하거나 상위 수준의 분석 요청을 안전하게 처리할 수 있는 경로를 제공하고,
- 신뢰할 수 있고 감사 가능한(auditable) 시각화 코드를 생성하며,
- 향후 스타일 제약, 접근성 검사, 도메인별 차트 정책과 같은 에이전트를 동일한 다중 경로, 피드백 기반 아키텍처에 손쉽게 플러그인할 수 있는 구조화되고 확장 가능한 프레임워크를 제시한다.
in solving your problems with Enhans!
We'll contact you shortly!