

저자: 서원덕, 안현진, 이승현
소속: Enhans AI Research
게재: Nineteenth ACM International Conference on Web Search and Data Mining (WSDM)
핵심요약
- 본 논문은 정보검색(Information Retrieval, IR)에서의 질의 확장을 위해 AMD (Agent-Mediated Dialogic) 라는 다중 에이전트 기반 프레임워크를 제안한다.
- 제안된 AMD는 Qwen2.5-7B-Instruct 모델을 사용하여 확장 질의를 생성하고, multilingual-e5-base 임베딩을 이용해 밀집 검색을 수행한다. BEIR의 6개 데이터셋과 TREC Deep Learning 2019/2020의 2개 데이터셋을 포함한 총 8개의 벤치마크에서 평가되었으며, 희소(sparse), 밀집(dense), RRF 융합(fusion) 검색 방식을 모두 지원한다.
- 이 프레임워크는 Enhans AI의 상용 에이전트들이 사용자의 의도를 더 정확히 파악할 수 있도록, 원래 질의를 여러 개의 목표 중심 하위 질의로 재구성하고 풍부한 질의 표현을 생성함으로써 웹 검색의 품질과 관련성을 향상시킨다.
- AMD는 풍부한 질의 임베딩이나 확장 용어를 제공하여 희소·밀집·융합 검색 파이프라인의 성능을 강화하고, 에이전트들이 고객에게 더 높은 가치의 인사이트와 차별화된 기능을 제공할 수 있도록 지원한다
초록 (Abstract)
질의 확장(Query Expansion)은 정보검색에서 초기 질의에 풍부한 정보를 보강해 검색 결과를 향상시키는 전통적인 방법이다. 최근 대형 언어모델(LLM) 기반 접근법들은 여러 프롬프트를 통해 의사 관련(pseudo-relevant) 콘텐츠나 확장 용어를 생성하지만, 이 방식들은 종종 맥락의 다양성이나 확정성이 부족한 결과를 낳는다.
이에 본 논문은 AMD (Agent-Mediated Dialogic Framework) 를 제안한다. AMD는 세 가지 역할을 수행하는 전문 에이전트 간의 대화적 탐구(dialogic inquiry) 과정을 통해 작동한다:
- 소크라테스식 질문 에이전트(Socratic Questioning Agent) – 초기 질의를 명확화, 가정 탐구, 함의 탐색의 세 가지 소크라테스식 사고 차원에 기반하여 세 개의 하위 질문으로 재구성한다.
- 대화형 응답 에이전트(Dialogic Answering Agent) – 각 하위 질문에 대한 의사 응답을 생성하여, 사용자의 의도에 맞는 다각적 관점을 반영한 풍부한 질의 표현을 만든다.
- 반성적 피드백 에이전트(Reflective Feedback Agent) – 생성된 응답들을 평가·정제하여, 가장 관련성 높고 유익한 정보만 남긴다.
이 다중 에이전트 구조는 탐구와 피드백 과정을 결합해, 정보 손실 없이 다양하고 의미론적으로 깊이 있는 질의 표현을 생성한다. BEIR 및 TREC 벤치마크에서의 실험 결과, 제안된 AMD는 기존 기법보다 우수한 검색 성능을 보여 정보검색 과제에 대한 강력한 솔루션임을 입증했다.
서론 (Introduction)
전통적인 정보검색(IR)에서의 질의 확장, 특히 PRF(Pseudo-Relevance Feedback) 계열 기법은 상위 랭크 문서에서 추출한 단어를 질의에 추가하여 검색 성능을 개선한다. 하지만 이러한 정적 단어 선택 방식은 사용자의 복합적 의도 중 일부만을 증폭시켜, 다양성과 깊이가 부족한 결과를 초래한다.
최근 LLM 기반 질의 확장 연구는 새로운 가능성을 열었다. 예를 들어,
- Q2D는 의사 문서를 생성하고,
- Q2C는 사고의 연쇄(Chain-of-Thought, COT) 기반으로 질의를 재구성하며,
- GenQREnsemble 및 GenQRFusion은 여러 프롬프트를 통한 키워드 중심 확장을 결합(fuse)한다.
하지만 이들 기법은 종종 동질적인 확장에 수렴하며, 가정이나 함의를 비판적으로 탐구할 메커니즘이 부재하고, 중복·잡음을 제거하는 체계적 피드백 절차가 부족하다. 결과적으로 질의의 다면성을 충분히 포착하지 못하고, 프롬프트 조합 수가 많아 계산 비용도 커진다.
이러한 한계를 극복하기 위해 본 논문은 질의 확장을 제안한다. AMD는 소크라테스식 분해(Socratic decomposition), 대화형 응답(Dialogic answering), 반성적 필터링(Reflective filtering) 세 단계를 결합한다.
- 먼저 Socratic Questioning Agent가 질의를 세 가지 차원의 하위 질문으로 분해한다(명확화, 가정 탐구, 함의 탐색).
- Dialogic Answering Agent는 각 질문에 대해 의사 응답을 생성해, 원래 질의의 의미를 다층적으로 확장한다.
- 마지막으로 Reflective Feedback Agent가 응답을 평가하고, 중복되거나 불필요한 내용을 제거해 정제된 확장을 생성한다.
결과적으로 AMD는 다양하면서도 필터링된 확장 질의를 제공하며, 희소·밀집·융합 검색 파이프라인 모두에 통합될 수 있어 효율성과 효과를 동시에 달성한다.
데이터셋 및 방법 (Datasets and Methods)
데이터셋:
AMD는 총 8개의 벤치마크 데이터셋에서 평가되었다.여섯 개는 BEIR 서브셋(Webis-Touché2020, SciFact, TREC-COVID, DBPedia-Entity, SCIDOCS, FIQA)이며,두 개는 TREC Deep Learning Passage Track 2019 및 2020이다.이 데이터셋들은 서로 다른 도메인과 질의/문서 단위를 포함하고 있어, 모델의 일반성과 강건성을 폭넓게 검증할 수 있다.
모델 구성:
에이전트 파이프라인은 Qwen2.5-7B-Instruct 모델을 사용해 질의 확장을 생성하며(temperature 0.5, 최대 길이 512),밀집 검색을 위해서는 multilingual-e5-base 모델을 사용하여질의와 문서를 코사인 유사도 기반으로 임베딩한다.희소 검색(sparse baseline)은 SciPy 기반 고속 구현체인 bm25s를 사용한 BM25를 적용한다.비교 실험에는 기존의 Q2D, Q2C, GenQREnsemble, GenQRFusion 모델들이각 논문에서 제시된 원래 설정(configuration)대로 수행되었다.
확장 질의 통합 방식:
AMD는 확장된 질의를 통합하는 세 가지 방식을 지원한다.
- 희소 연결(Sparse Concatenation)원본 질의를 세 번 복제(replicate) 한 뒤,그 뒤에 모든 정제된 의사 응답(refined pseudo-answers) 을 [SEP] 구분자로 이어 붙인다.이 방식은 핵심 검색 신호(core signals)를 강화하면서, 정제된 문맥(context)을 주입해 질의 표현을 풍부하게 만든다.
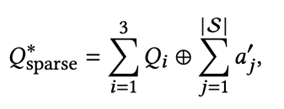
- 밀집 융합(Dense Fusion)최종 질의 임베딩을 다음과 같은 가중합으로 구성한다:
0.7 × 임베딩(원본 질의) + 0.3 × 평균(정제된 응답 임베딩).이 방식은 이전 연구들에서 사용된 가중 합산 기반 집계(aggregation) 방식과 유사하며, 확장 질의를 임베딩 단계에서 직접 통합해 표현한다.
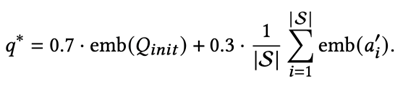
- RRF 융합(Fusion)각 정제된 응답을 별개의 확장 질의(expanded query) 로 간주하고, 각각 독립적으로 검색을 수행한 뒤 Reciprocal Rank Fusion(RRF) 으로 결과를 병합한다.이때 k=60을 사용해 낮은 순위 문서들의 영향을 완화하고, 각 결과의 역순위 점수(fused score) 를 합산해 최종 재정렬(rerank)을 수행한다.

프레임워크 상세 (Agent-Mediated Dialogic AMD)

- Socratic Questioning Agent단일 LLM 패스에서 세 개의 하위 질의를 생성한다.각 질의는 소크라테스식 사고의 세 가지 차원에 대응한다:
- Clarification (명확화): 사용자의 의도를 세분화하거나 모호성을 제거한다.
- Assumption probing (가정 탐구): 숨겨진 전제나 대안적 관점을 드러낸다.
- Implication probing (함의 탐색): 파생 효과, 관련 측면 또는 결과를 탐색한다.
- Dialogic Answering Agent
각 하위 질문에 대해 의사 응답(pseudo-answer) 을 생성한다.이 응답들은 짧고 집중된 형태의 대체 문서(surrogate document) 역할을 하며, 하나의 추론(inference) 과정에서 병렬적으로 생성되어 효율성을 높인다.이를 통해 원래 질의의 의미를 여러 관점에서 풍부하게 확장할 수 있다. - Reflective Feedback Agent
세 개의 (질문–응답) 쌍을 원래 질의의 맥락에서 평가하고, 응답을 재작성하여 불명확하거나 중복되거나 비관련된 내용을 걸러낸다.대신 정보성이 높고, 사용자 의도에 부합하는 근거(evidence) 만을 유지한다.이 에이전트는 별도의 파인튜닝 없이도 작동하며, 따라서 실용성과 이식성(portability)이 높다.최종적으로 정제된 응답 집합이 확장 질의 풀로 사용되어, 선택한 검색 통합 방식(희소 / 밀집 / RRF)에 입력된다.
실험 결과 (Experimental Results)

희소 검색 ( Sparse retieval, BM25 기반):
AMD는 BEIR 전체 평균에서 가장 높은 성능을 보였다.예를 들어, BEIR 평균 nDCG@10은 0.4352로, BM25(0.3672), Q2C(0.4147), Q2D(0.4193)을 모두 능가했다.개별 데이터셋에서도 일관된 우세를 보였으며(Webis 0.3896, SciFact 0.7021 등), TREC DL 2019·2020에서도 평균 성능이 향상되었다(DL’19: 0.5870, DL’20: 0.5818).이는 Q2D/Q2C보다 약간 높고, BM25 대비 확연히 개선된 결과다.
밀집 검색 (Dense retrieval, E5-base):
AMD는 밀집 검색에서도 BEIR 평균 0.4707을 기록해 기존 LLM 기반 확장 기법보다 우수한 성능을 보였다. TREC DL 2019·2020에서도 각각 0.5752, 0.5847을 달성했다.여기서 0.7/0.3 가중 합산 방식은 원본 의도의 핵심 신호를 유지하면서, 여러 관점에서 정제된 정보 신호를 함께 주입하는 역할을 한다.
RRF 융합 (RRF fusion)
AMD는 GenQRFusion(최대 10개의 키워드 프롬프트 조합)보다 높은 BEIR 평균 점수(0.4113 vs 0.3897)를 기록했고, TREC DL 2019(0.5041), DL 2020(0.4819)에서도 우세했다.이는 적은 수의 고품질 확장 질의가 다수의 노이즈 섞인 조합보다 더 효과적임을 보여준다. 또한 계산 비용도 더 낮다.

Ablation (Feedback 제거 실험):
Reflective Feedback Agent를 제거하면 평균 점수가 일관되게 하락하고 변동성이 커진다.예를 들어, 희소 설정에서는 BEIR 평균이 0.4352 → 0.4295로 감소하며, 밀집 설정에서는 0.4707 → 0.4658로 하락한다.RRF의 경우 BEIR에서는 0.4113 → 0.4147로 소폭 상승하지만, TREC-DL 성능은 오히려 약화되었다.즉, 피드백 단계를 생략해도 AMD는 여전히 경쟁력이 있으나, Feedback 단계가 전체 성능을 안정화시키고 평균 향상을 보장한다.
결론 (Conclusion)
AMD는 단순하지만 강력한 원리를 실현한다:
“구조화(Socratic) → 다양화(Dialogic) → 정제(Reflective)”
이를 통해 생성된 확장 질의는 다양하면서도 필터링된, 그리고 의도에 충실한 표현으로 구성되어, 희소·밀집·융합 검색 파이프라인 전반에서 일관된 성능 향상을 달성한다.
이 프레임워크는
- 실용적: 질문과 응답을 한 번의 패스로 생성하고, Feedback Agent는 파인튜닝 없이 사용 가능하며,
- 모듈형: 기존 검색기(BM25, E5 등)나 융합 스킴과 손쉽게 결합 가능하다.
한계점: Feedback Agent가 평가·재작성에 특화되어 학습된 모델이 아니기 때문에
일부 비관련 정보가 남을 수 있다.
향후 연구: Feedback 모듈의 파인튜닝 및
각 소크라테스 질문 유형이 도메인별로 어떤 기여를 하는지에 대한 정성적 분석을 통해, 더 해석 가능하고 도메인 지향적인 확장 방식을 모색할 예정이다.
in solving your problems with Enhans!
We'll contact you shortly!